【paper reading】Adaptive Cross-Modal Few-Shot Learning

一句话总结
本文提出了一种自适应模态混合机制,可以根据要学习的新图像类别自适应地组合来自视觉和语言两种模态的信息,比模态对齐方法更适用于小样本学习。
论文信息
- 作者:Chen Xing, Negar Rostamzadeh, Boris N. Oreshkin, Pedro H. O. Pinheiro
- 出处:NeurIPS 2019
- 机构:Element AI, Montreal, Canada; Nankai University
- 关键词:few-shot learning, metric learning, multimodal
- 论文链接
- 开源代码:ElementAI/am3
- 其他资料:
内容简记
背景
当来自视觉模态的数据有限时,利用辅助模态(例如,属性,未标记的文本语料库)来帮助图像分类主要由无样本学习(Zero-Shot Learning, ZSL)驱动。与少样本学习(Few-Shot Learning, FSL)对比,无样本学习没有少量标记样本来帮助识别新类别。大多数方法在训练阶段将两种模态对齐,以此迫使模态被映射在一起并具有相同的语义结构。这样,来自辅助模态的知识在测试时被迁移到视觉方面用于识别新类别。

然而,视觉和自然语言语义特征根据定义具有不同的结构。对于不同的概念,视觉特征可能比文本特征更丰富和更具辨识度;而对于另一些概念,可能情况是相反的。此外,当图像数量非常少时,从视觉模态提供的信息往往是嘈杂和局部的,而(从无监督的文本语料库中学习的)语义表示可以提供强大的先验知识和上下文以帮助学习。在无样本学习中,测试阶段没有给视觉信息,因此算法只能完全依靠辅助模态(例如,文本);而当有标记的图像样本数量很多时,神经网络倾向于忽略辅助模态,因为它已经有能力通过大量样本学会泛化。小样本学处于在这两个极端情况的中间态,因此我们可以假设视觉和语义信息都可用于小样本学习。
因此,比起将两种模态对齐并进行知识迁移,在测试阶段进行从两种模态获得信息的小样本学习时,最好将各模态视为独立的知识来源,并根据不同的场景自适应地利用不同的模态。
根据上述分析,本文提出自适应模态混合机制(Adaptive Modality Mixture Mechanism, AM3),可以根据要学习的新图像类别自适应地组合来自两种模态的信息,用于小样本学习。
实验表明,效果超过当前的单模态小样本学习方法和模态对齐方法。另外,试验还表明,该模型可以有效调整其对两种模态的关注。当镜头数量非常小时,性能的提升特别高。
方法
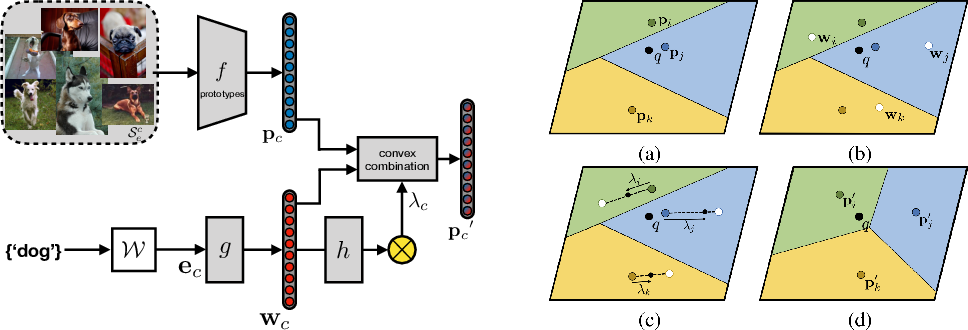
本文提出的自适应模态混合机制(Adaptive Modality Mixture Mechanism, AM3)可以应用于任何基于度量的方法。本文选用原型网络(Prototypical Networks)和 TADAM。对于类别 $c$,新的原型(prototype)计算如下:
$$
\mathbf{p}_{c}^{\prime}=\lambda_{c} \cdot \mathbf{p}_{c}+\left(1-\lambda_{c}\right) \cdot \mathbf{w}_{c}
$$
其中,$\mathbf{w}_{c}=g\left(\mathbf{e}_{c}\right)$ 是一个对于类别 $c$ 的标签嵌入的转换版本,$\mathbf{e}_{c}$ 是对于类别 $c$ 标签的预训练词向量,而转换 $g : \mathbb{R}^{n_{w}} \rightarrow \mathbb{R}^{n_{p}}$ 让两个模态处于同一空间并可以合并。$\lambda_{c}$ 是自适应混合系数(adaptive mixture coefficient):
$$
\lambda_{c}=\frac{1}{1+\exp \left(-h\left(\mathbf{w}_{c}\right)\right)}
$$
$h$ 是自适应混合网络(adaptive mixing network)。自适应混合系数 $\lambda_{c}$ 可以根据不同的变量进行控制。
训练过程与原始的原型网络相似,只是距离度量变为
$$
p_{\theta}\left(y=c | q_{t}, S_{e}, \mathcal{W}\right)=\frac{\exp \left(-d\left(f\left(q_{t}\right), \mathbf{p}_{c}^{\prime}\right)\right)}{\sum_{k} \exp \left(-d\left(f\left(q_{t}\right), \mathbf{p}_{k}^{\prime}\right)\right)}
$$
损失是每个查询集样本的真类的负对数似然(the negative loglikelihood of the true class of each query sample):
$$
\mathcal{L}(\theta)=\underset{\left(\mathcal{S}_{e}, \mathcal{Q}_{e}\right)}{\mathbb{E}}-\sum_{t=1}^{Q_{e}} \log p_{\theta}\left(y_{t} | q_{t}, \mathcal{S}_{e}\right)
$$
其中,$\mathcal{S}_{e}$ 是支撑集,$\mathcal{Q}_{e}$ 是查询集。
实验
对比实验
数据集:
- miniImageNet [2]
- tieredImageNet [3]
- CUB-200 [4]:这是一个无样本学习数据集。考虑到大多数模态对齐方法没有在小样本学习数据集上有公开的实验结果,这个数据集用于将 AM3 与模态对齐方法进行对比
本文在 和 tieredImageNet [3],将 AM3 与三种基线进行对比:单模态 FSL 方法,模态对齐方法,模态对齐方法的基于度量的扩展。
baselines:
- 单模态 FSL 方法:MAML、LEO [6]、原型网络、TADAM [5] 等;
- 模态对齐方法:CADA-VAE [7] 等;
- 模态对齐方法的基于度量的扩展:使用了基于度量的损失以及原型网络的训练方式(episode training)。
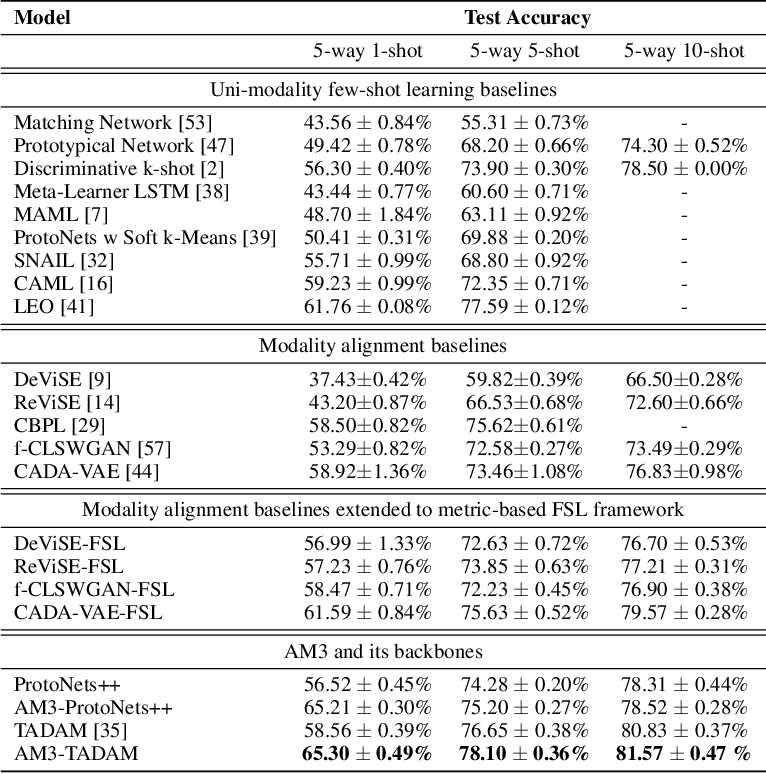
在 miniImageNet 数据集上的分类结果:
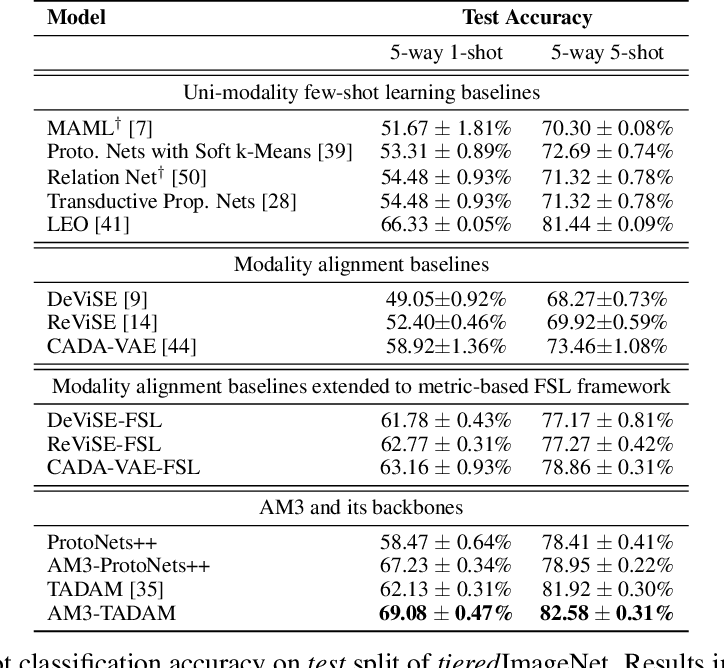
在 tieredImageNet 数据集上的分类结果:
结论:
- 在所有数据集上,AM3 的表现都优于其主干方法。说明在正确使用时,文本模态可以帮助提高基于度量的 FSL 学习框架的性能;
- AM3(主干方法选用 TADAM)取得 SOTA,且当 shot 数(即样本数)越少时,效果提升越多。说明当视觉模态提供的信息越少时,语义信息对分类的帮助越大;
- 当扩展到基于度量、episodic、FSL 框架时时,所有模态对齐方法的表现都显著提升。然而扩展前后这些模态对齐方法都比单模态 FSL 方法的 SOTA 要差。说明尽管模态对齐方法对于 ZSL 中的跨模态是有效的,但并不适合 FSL。一个可能的原因是,两个不同的结构被迫对齐导致双方的一些信息可能损失。
在 CUB-200 数据集上的分类结果:
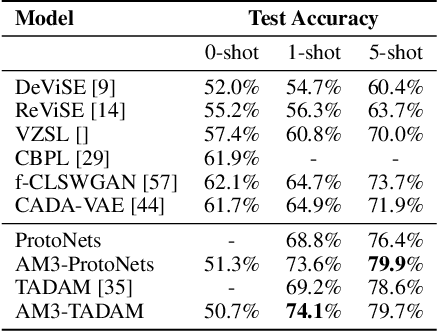
结论:对于无样本学习场景,AM3 降级为最简单的模态对齐方法,将文本语义空间映射到视觉空间。因此,在没有自适应机制的情况下,AM3 的表现与 DeViSE 大致相同。说明自适应机制在 FSL 场景中观察到的性能提升中起主要作用。
自适应机制分析
对本文提出的自适应机制进行定量分析:
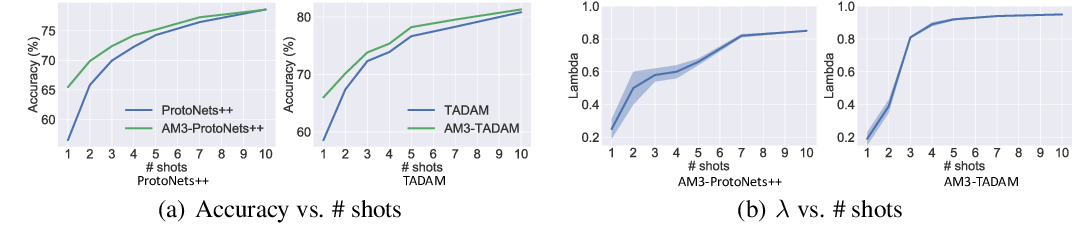
结论:
- 当 shot 数(即样本数)增加时,AM3 与其主干方法的表现差距减小;
- 自适应混合系数 $\lambda_{c}$ 的平均值与 shot 数有关,当 shot 数减小时,AM3 在文本模态上的权重更大(在视觉模态上更小)。这种趋势表明,当视觉信息非常少时,AM3 可以自动将焦点更多地调整到文本模态以帮助分类;
- 当 $\lambda_{c}$ 的方差随着 shot 数增加而减小时,AM3 与其主干方法的性能差距也会缩小。这表明 AM3 在类别级别的适应性对性能提升有非常重要的作用(???觉得有点牵强)。
消融实验
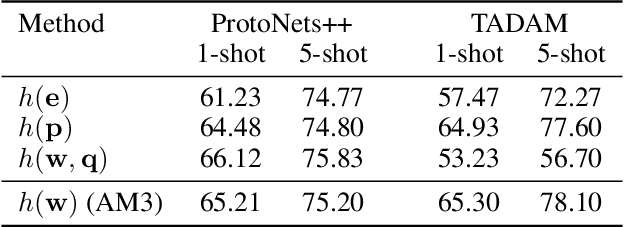
所以选用变换后的语义特征来做自适应机制是实验得到的最好选择。
个人笔记
理解
我个人认为,转换 $g$ 本质上还是一种表示空间的强行对齐,会破坏模态本身的自然结构。因此,可能可以考虑一种更好的特征组合与自适应调整方式。
参考论文
- [1] Zero-shot learning-the good, the bad and the ugly, CVPR 2017.
- [2] Matching networks for one shot learning, NIPS 2016.
- [3] Meta-learning for semi-supervised few-shot classification, ICLR 2018.
- [4] Caltech-UCSD Birds 200, Technical Report CNS-TR-2010-001, 2010.
- [5] Tadam: Task dependent adaptive metric for improved few-shot learning, NeurIPS 2018.
- [6] Meta-learning with latent embedding optimization, ICML 2016.
- [7] Generalized zero-and few-shot learning via aligned variational autoencoders, CVPR 2019.