【paper reading】基于 Web 的问答系统综述
原文链接:基于 Web 的问答系统综述
作者:李舟军,李水华
简介:详细介绍了基于 Web 的问答系统的研究背景、架构及其问题分析、信息检索、答案抽取这三大关键技术的研究进展,并分析了基于 Web 的问答系统所面临的问题。
选读原因:选了一篇中文的基于 Web 的问答系统综述,和手头上工作比较贴近,来对接下来的研究方向有个大致的了解和思考,因此记录也比较详细。
概述
问答系统(Question Answering, QA)以自然语言为输入与输出,理解用户的查询意图后,通过一系列的检索、分析与处理,返回精确、简练的答案。
根据问答系统知识来源的不同,该文将问答系统分为 3 类:
- 基于知识库的问答系统(Qustion Answering over Knowledge Bases, KBQA):主要以知识库作为问答系统的知识来源;
- 基于社区的问答系统(Community-based Question Answering, CQA):主要以问答社区(如知乎、百度知道等)作为问答系统的知识来源;
- 基于 Web 的问答系统(Web-based Question Answering, WQA):以开放的互联网上的 Web 文档作为问答系统的知识来源,从搜索引擎上返回的相关网页片段中抽取出用户所提问题的答案。
其中,WQA 系统同时具有搜索引擎和问答系统的优点,与时俱进,不断更新。
WQA 系统
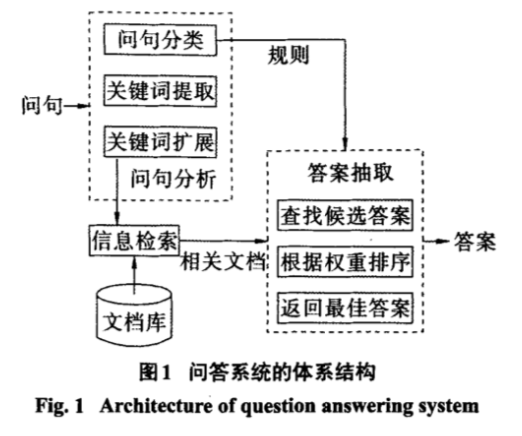
经典的 WQA 系统通常由以下 3 个模块构成(其他 QA 系统各模块大体一致,功能有所不同。上图来源[1]):
- 问题分析模块:根据用户的查询意图生成相应的查询语句,可能包含对问题的分类、提取问题的关键词或者生成一些其他描述用户查询意图的中间数据;
- 信息检索模块:将问题分析模块得到的查询语句或关键词提交给搜索引擎,并整理返回的搜索结果来得到可能包含正确答案的网页片段(性能瓶颈);
- 答案抽取模块:利用信息抽取技术,从网页片段中抽取答案,可能需要用到问题分析模块得到的问题类别、关键词等数据。
问题分析模块
流程:
- 分词
- 问题分类:问题的类别是反应用户提问意图的重要信息
- 问题重写:便于搜索引擎理解问题语义
问题分类
问题分类的作用体现在:
- 能够有效减少候选答案空间,提高系统返回答案的准确性。例如,一个问句被分类为时间类,则在答案抽取阶段,系统把不含时间的候选句子过滤掉;
- 决定答案喧杂策略,根据不同的问句类型调节对不同问题的答案选择策略。例如,对于“安徽省的简称是什么”,分析出其询问地点类别,抽取文档库中地点类的文档作为候选答案。

表一为国际权威的 UIUC 问句分类体系,针对英文分类。表二是哈工大定义的中文问句分类体系。
很多 WQA 系统采用规则分类器对问题进行分类。最简单的规则可以是通过问题是否包含某个词来分类,而比较复杂的规则包括基于语义模式匹配的问题分类[2]。如果没有一条规则能够与问题匹配成功,则借助一些统计机器学习的方法分类,例如 SVM、RNN 等。
关键词提取和扩展
关键词既可作为搜索引擎的输入,也可辅助答案的抽取过程。WQA 系统通常在分词、取出停用词之后进行关键词的提取,并将名词、动词、形容词等作为关键词。因此可以用一些简单规则提取,例如“所有带形容词的名词都是关键词”等。也可以分析问题的语法结构,抽取主语、宾语作为关键词[3]。
关键词的扩展主要用于解决关键词的同义词的匹配问题,通常需要一些同义词词库进行辅助。
问题重写
当问题本身(而非关键词)作为搜索引擎的输入时,可能较难领会语义,此时需要对问题进行重写。一些启发式的方法依靠简单的字符串操作(替换、拼接、删除)来实现问题重写,也有较为复杂的优化方法,例如定义一个针对问题的操作集合,然后利用概率模型选择最合适的操作来重写问题[4]。
信息检索模块
信息检索模块的实现可以调用搜索引擎提供的接口,也可以利用爬虫技术。搜索引擎所具有的高质量摘要技术能过滤原始网页的噪音数据,因此无需抓取解析原始网页。
答案抽取模块
答案抽取模块是 WQA 系统中的重点和难点,通常包括两个步骤:
- 候选答案抽取:从网页片段中抽取出候选答案;
- 候选答案排序:对候选答案进行排序,得到最佳答案。
候选答案抽取
抽取候选答案的几种典型方法:
- 手工编辑或自动生成名词词典,将词典中的所有名词都作为候选答案。这种做法的候选答案集非常大,因此候选答案排序以及维护难度很大,难以更新以应对新的领域和新的概念;
- 利用命名实体识别(Named Entity Recognition, NER)工具,抽取命名实体作为候选答案。具体效果受问题分类算法和命名实体识别算法效果的影响;
- 根据手工编辑或自动生成的文本模式抽取候选答案。准确率较高,但匹配较为死板,无法适应新的数据。
候选答案排序
候选答案排序及最佳答案选择的几种典型方法:
- 采用向量空间模型(Vector Space Model, VSM)计算候选答案与问题的相似度,并以此进行排序[5];
- 根据语法结构判断候选答案与问题的匹配度,并以此进行排序;
- 根据词汇特征、相似度特征、统计特征等多种特征进行综合排序。
WQA 面临的主要问题
- 问题分类有待改善:问题分类的本质是短文本分类,受限于特征稀缺,分类器效果有待提升;
- 同义句子的理解需要解决:同义词的使用和句法结构的变化使得 WQA 系统难以准确抽取答案;
- 高质量的 QA 对难以获取:缺少相关数据;
- 利用跨语言语料能力较差:网页片段可能存在多种语言,WQA 系统难以利用多种语言的文本数据来回答某一种特定语言的问题;
- 通用型不足:回答通用领域问题的能力尚有待进一步增强;
- 处理复杂问题的能力不足:对于定义型、原因型、关系型、比较型、方法型等问题难以给出满意的回答。
WQA 的发展趋势
- 与其他问答系统的融合;
- 通过答案摘要生成答案;
- 自动生成高质量问答对数据;
- 提升 WQA 系统处理复杂问题的能力;
- 跨语言能力、跨领域能力的进一步增强;
- 与语音识别、语音生成等工具的进一步结合;
- 辅助机器人。
文献
[1] 镇丽华, 王小林, 杨思春. 自动问答系统中问句分类研究综述[J]. 安徽工业大学学报(自科版), 2015, 32(1):48-54.
[2] LI X, HU D, LI H, et al. Automatic question answering from Web documents[J]. Wuhan University Journal of Natural Sciences, 2007, 12(5):875 880.
[3] LIU Z J, WANG X L, CHEN Q C, et al. A Chinese question answering system based on Web search [C]. International Conference on Machine Learning and Cybernetics, Lanzhou: IEEE, 2014:816-820.
[4] CHALI Y, HASAN S A, MOJAHID M. A reinforcement learning formulation to the complex question answering problem
[J]. Information Processing & Management, 2015, 51(3):252 272.
[5] 余正涛,樊孝忠,郭剑毅,等. 基于潜在语义分析的汉语问答系统答案提取[J]. 计算机学报,2006,29(10):1889—1893.