【paper reading】Deep Learning for Sentiment Analysis:A Survey
原文链接:Deep Learning for Sentiment Analysis: A Survey
作者:Lei Zhang, Shuai Wang, Bing Liu
简介:该文首先对深度学习的技术进行了概述,然后对基于深度学习的情感分析研究进行了全面的综述。
选读原因:之前想把手头情感分析的工作再进一步推动一下,因此选择在 arXiv 上找一篇相关综述进行阅读。同样,也是对自然语言处理中的一些概念和技术的了解和复习。这篇综述相对较新,质量很高,而且作者之一刘兵老师是情感分析领域最有影响力的学者之一。当然,综述只是帮助对某一研究领域建立一个初步的印象,要想真正开始深入还是得读海量的 paper + 选择复现。这篇综述中对相关工作建立表格详细介绍,因此原文仍值得一看。
研究概况
研究背景
情感分析(Sentiment analysis)或意见挖掘(Opinion mining)是对人群对于产品、服务、组织、个体、问题、事件、话题等实体的意见、情感、情绪、评价、态度的计算研究。鉴于网络社交媒体的风行,我们拥有了海量的情绪化数据。情感分析已经成为自然语言处理中最有吸引力的研究领域之一,它与管理科学、社会科学领域有交集。
早期的情感分析技术包括监督方法(支持向量机、最大熵、朴素贝叶斯等监督机器学习方法)和无监督方法(包括利用情感词典、语法分析和句法模式的各种方法),而深度学习走红后,其应用到情感分析的出色效果催生大量基于深度学习的情感分析研究。
具体内容
相关技术
这里简单概括一下文中对各种深度学习技术的介绍,同时也是对我知道的点做一个复习。DNN、CNN、RNN、Attention 就不介绍了,如果想了解欢迎看我的吴恩达《深度学习》系列课程笔记。
词嵌入
NLP 中的许多深度学习模型需要词嵌入作为输入特征。词嵌入将词转换为包含实数的向量,并做从高维稀疏向量空间(通常是 One-hot 编码得到的词向量)到低维密集向量空间的处理。嵌入向量的每个维度都代表一个单词的潜在特征,因此这些向量可以编码语言的规律和模式。
Word2Vec 和 Glove 是两种常用于获得词嵌入的方法。前者是一种神经网络预测模型,可以从文本中学习词嵌入;后者是在一个全局单词共现矩阵的非零项上进行训练。
自动编码器
自动编码器(Autoencoder)是一种主要用于数据降维或者特征抽取的的自监督学习算法。
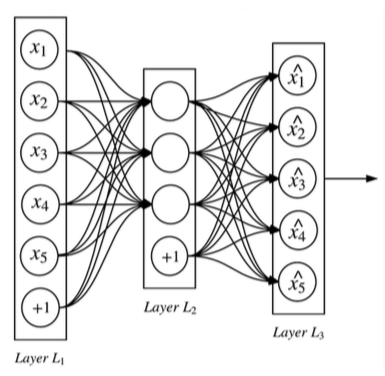
一个三层的神经网络,其中隐藏层被看作一个编码器和解码器,而输出层的目标值和输入层输入值一致。这样,隐含层是尽量保证输出数据等于输入数据的,使得隐含层能够抓住输入数据的特点,使其特征保持不变。设编码函数为h()、解码函数为g(),则目标是最小化损失函数loss(x, g(h(x))),而最后获得的隐藏层激活值即是自动编码器捕捉到的训练数据中最显著的特征,权重矩阵W则可作为神经网络训练的初始值。
自动编码器的一种扩展是去噪自动编码器(Denoising Autoencoder,DAE)。其目标是最小化loss(x, g(h(~x))),其中~x是被某种噪声损坏的x,使得隐藏层学习更健壮的特征。
LSTM
LSTM(Long Short Term Memory,长短期记忆)是一种特殊的 RNN,用于缓解 RNN 梯度爆炸和梯度消失的问题。
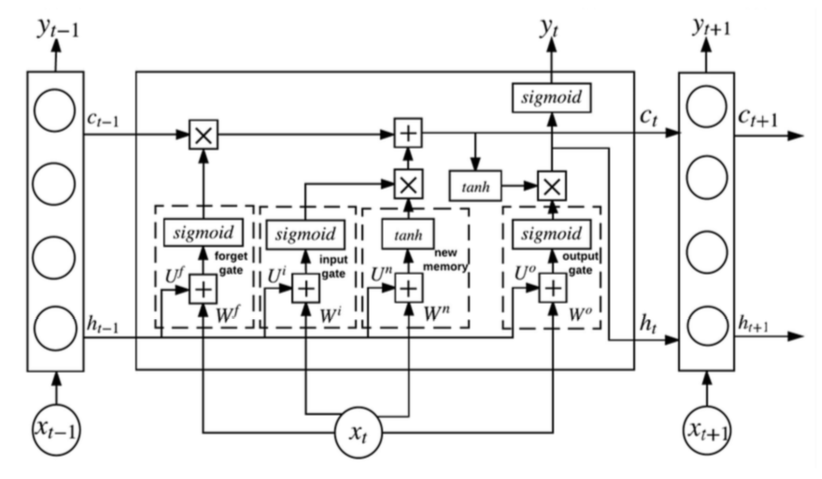
在 LSTM 的一个可供重复使用的结构中,有四个层相互作用,并有 hidden state 和 cell state 两个 states。
在时间步 $t$,LSTM 首先决定是否将 cell state 中的信息丢弃。这个决定由使用 sigmoid 函数的层 $f_t$(称为“遗忘门”)。函数使用 $h_{t-1}$(前一个隐藏层的输出)和 $x_t$(当前输入),输出一个 [0, 1] 的值,1 表示完全保留,0 表示完全丢弃。
$$f_t = \sigma(W^fx_t + U^fh_{t-1})$$
之后,LSTM 决定存储在 cell state 中的新的信息。第一步,使用 sigmoid 函数的“输入门” $i_t$ 决定 LSTM 更新的值;第二步,一个使用 tanh 函数的层创建一个候选值向量 $\tilde{C_t}$ 来加到 cell state 上。
$$i_t = \sigma(W^ix_t + U^ih_{t-1})$$
$$\tilde{C_t} = tanh(W^nx_t + U^nh_{t-1})$$
然后用以下公式更新 $C_t$。其中遗忘门 $f_t$ 可以控制经过的梯度,以缓解梯度消失或梯度爆炸的问题。
$$C_t = f_t * C_{t-1} + i_t * \tilde{C_t}$$
最后,LSTM 基于 cell state 决定输出。这里用到一个使用 sigmoid 函数的“输出门”。
$$o_t = \sigma(W^o x_t + U^o h_{t-1})$$
$$h_t = o_t * tanh(C_t)$$
LSTM 常用于序列数据,但也可用于树结构数据。树结构 LSTM(Tree-structured LSTM)在表示句子含义上比普通的 LSTM 表现更好。[1]
递归神经网络(RecNN)
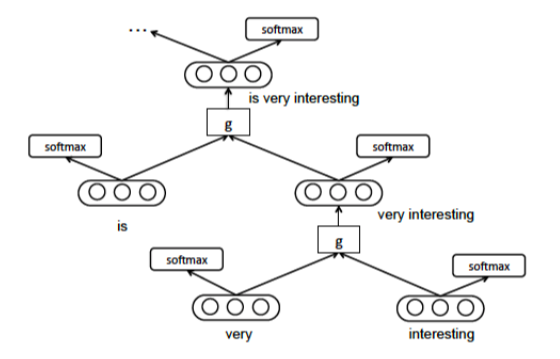
递归神经网络(RecNN)通常用于从数据中学习有向无环图结构(例如树结构)。给定句子的结构表示形式(例如解析树),RecNN 以自下而上的方式递归地生成父表示形式(一般为向量),通过组合 tokens 来生成短语表示形式,最终生成整个句子。然后可以使用句子级表示形式对给定的输入句子进行最终分类(例如情感分类)。
情感分析任务
情感分析可以根据分析对象的粒度分为三个 level:
- Document level:对文章做总体的情感分类。
- Sentence level:一般先分类为有情感和无情感的(这个过程被称作 subjectivity classification),然后再对有情感的句子进行分类。
- Aspect level:任务是提取人们对实体和实体的各个方面/特征所表达的意见。因此,它包含了方面抽取、情感抽取和情感分类。
Document level
如果是多分类,例如 1-5 星,可以考虑用回归实现。
比较传统的方法是基于词袋模型,对每篇文档定长的数值化特征向量,长度为词典中的词量,值可以是词频或者 TF-IDF。词袋模型的缺点是文本中单词顺序和上下文所蕴含的信息被完全丢弃,n-gram 可以略微减少其影响,但是增加了数据稀疏和高维等问题。另外,词袋模型无法表示语义。
由此引入词嵌入和神经网络。神经网络可能只用于提取文本特征/表示,这些特征用于非神经网络的分类器中,以获得一个结合二者优点的分类器。
鉴于文章常有较长的依赖关系,注意力机制在文章级别的情感分类中也经常使用。
Sentence level
由于句子相较文章来说要短得多,信息量更小,因此一些语义和句法的信息会对 Sentence level 的情感分析有帮助。早期研究中,会用包括解析树、情感词典、词性标注等来提供这些信息。但现在,CNN 和 RNN 使得不再需要用解析树从句子中提取特征,取而代之的是已经将语义、句法信息编码在内的词嵌入作为输入。同时 CNN 和 RNN 也会学习词与词之间的关系信息。
Aspect level
在 Aspect level 的情感分析中,我们不只关注情感本身,还关注它所联系的目标对象(target)。一个对象通常是一个实体或者实体的某一方面,它们有时也被称为 aspect。
例如,在 “the screen is very clear but the battery life is too short.” 这一句话中,如果 target aspect 是 “screen”,那么情感是正面的;但如果 target aspect 是 “battery life”,那么情感是负面的。
Aspect level 的情感分析难度较大,因为需要捕捉目标对象和上下文(context)的语义联系。
三个重要任务:
- 生成目标对象上下文的表示:可以使用之前提到的文本表示方法;
- 生成目标对象的表示:可以类似词嵌入,学习一个文本嵌入;
- 识别对于特定目标对象的重要情感上下文:目前常用注意力机制处理,但是还没有统治性的方法出现。
其他
还有一些其他的研究内容,包括:
- Aspect extraction and categorization:实体对象的抽取与分类;
- Opinion expression extraction:意见表达词的抽取;
- Sentiment composition:直译为情感成分,认为意见表达的情感取向是由其构成成分的意义和语法结构决定的;
- Opinion holder extraction:抽取意见的持有者;
- Temporal opinion mining:情感或意见是有时效性的,因此预测未来的情感或意见也是一个可研究的问题;
- Sarcasm analysis:分析是否为讽刺;
- Emotion analysis:我将这里的 Emotion 翻译成情绪,比情感更主观;
- Multimodal data for sentiment analysis:多模态数据,例如包含文本、视觉和声学信息的数据,被用来帮助情感分析;
- Resource-poor language and multilingual sentiment analysis:资源贫乏语言和多语言的情感分析;
- Sentiment intersubjectivity:情感主体间性,研究语言的表层形式与相应的抽象概念之间的差距;
- Lexicon Expansion:词汇扩展;
- Financial Volatility Prediction:根据情感分析进行金融波动预测;
- Opinion Recommendation:意见推荐,将用户写好的关于商品的意见选择推荐给其他用户;
- Stance Detection:立场检测,分析例如政治 twitter 等数据隐含的政治立场。
由此可见,情感分析仍然是一个值得深挖的研究方向,并且在深度学习的结合下,有更多的研究和应用出现。
文献
[1] Tai K.S, Socher R, Manning C. D. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL 2015), 2015.