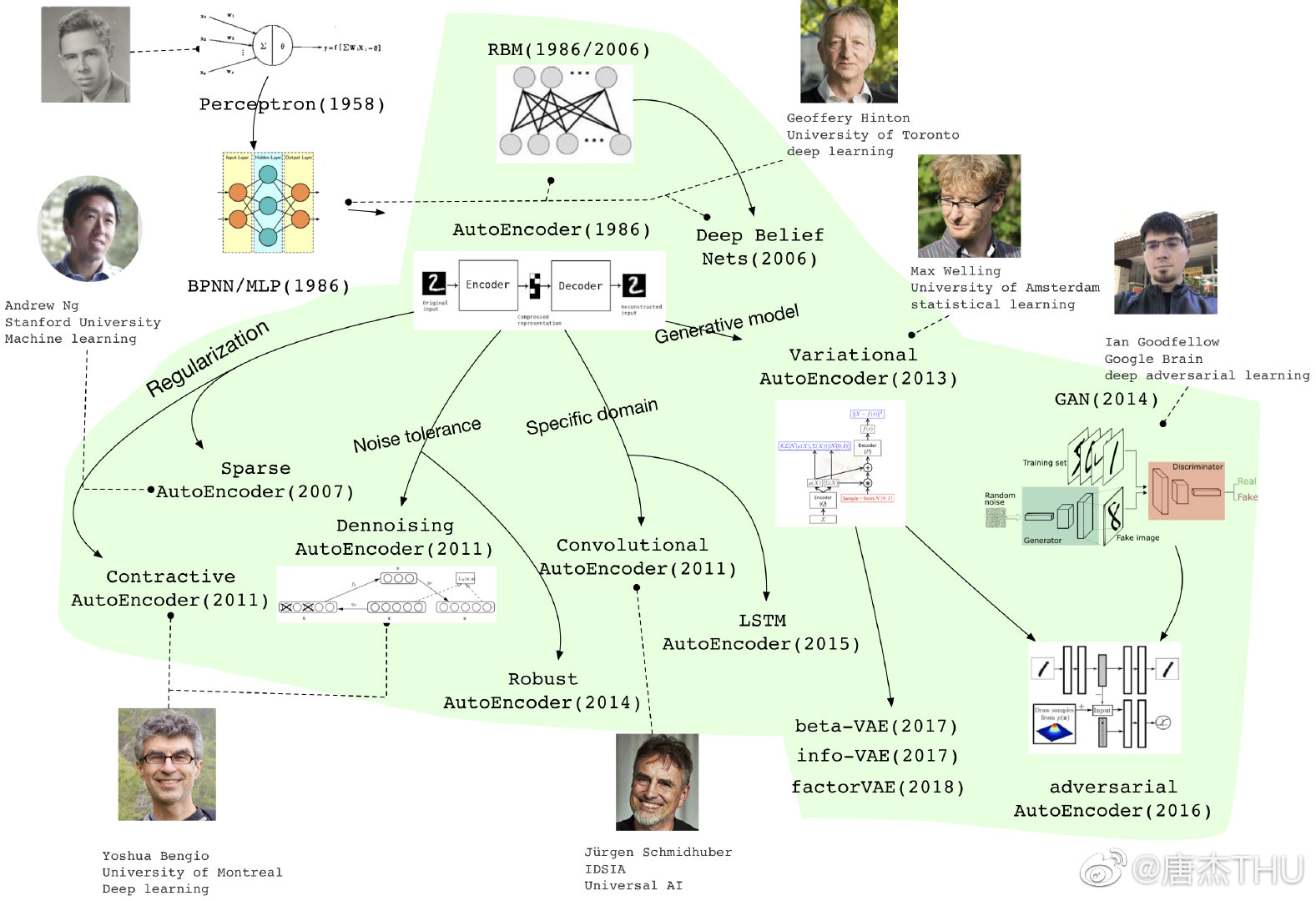
【paper reading】2021 小样本分割论文选读
根据手头想法的需要,读一读 2021 年顶会顶刊的小样本分割相关论文并做笔记于此。有开源代码的论文优先,持续更新。
- Prior Guided Feature Enrichment Network for Few-Shot Segmentation (TPAMI 2020)
- Few-Shot Segmentation Via Cycle-Consistent Transformer (NeurIPS 2021)
- Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer (ICCV 2021)
- Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need? (CVPR 2021)
- Self-Guided and Cross-Guided Learning for Few-Shot Segmentation (CVPR 2021)
- Adaptive Prototype Learning and Allocation for Few-Shot Segmentation (CVPR 2021)
- Mining Latent Classes for Few-shot Segmentation (ICCV 2021)
- Few-Shot 3D Point Cloud Semantic Segmentation (CVPR 2021)