【paper reading】Composing Text and Image for Image Retrieval - An Empirical Odyssey

一句话总结
作为第一篇研究用于图像检索的图像与文本特征组合问题的论文,本文提出一种采用门控机制和残差连接的特征组合方式,确保修改后的特征处于目标图像特征处在相同空间中,并通过度量学习的方式达到 SOTA。
论文信息
- 作者:Nam S. Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, James Hays
- 出处:CVPR 2019
- 机构:Google AI, Stanford
- 关键词:Image retrieval, multimodal, metric learning, feature composition
- 论文链接
- 开源代码:https://github.com/google/tirg
- 其他资料:
内容简记
背景
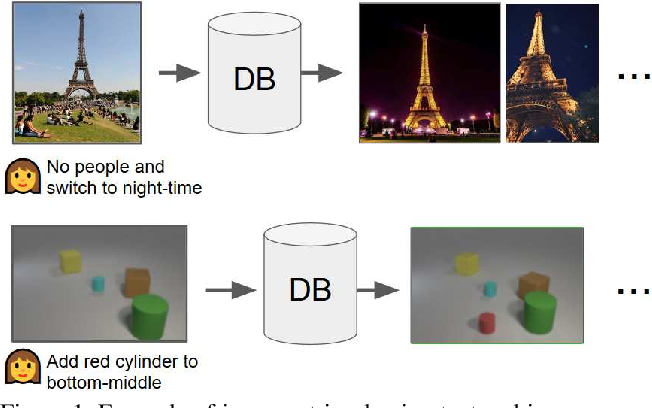
本文展示在一种典型的图像检索场景——用户使用已经找到的图像作为参考,然后用文本表达其与查询意图的差异,来检索相关图像——下的解决方案。这种场景与基于属性的产品检索密切相关,但不同之处在于文本可以由多个词语组成,而不是单个属性。
主要的研究问题在于当由两种不同的输入模态时,如何表示查询,即如何为查询学习有意义的跨模态特征组合以便找到目标图像。文本与图像间的特征组合方法,从简单的拼接、浅前馈网络,到先进的机制(如关系 [1] 或参数哈希 [2])已经广泛应用于相关问题。在本文研究的问题中,文本应该修改查询图像的特征,但是希望修改后得到的特征向量和目标图像处在相同的空间。因此,本文提出“文本图像残差门控”(Text Image Residual Gating,TIRG),通过门控机制和残差连接来让文本修改图片特征。该方法在三个数据集上达到 SOTA。
已有的特征组合方法(即本文进行比较的 baselines):
- 拼接输入 MLP;
- Show and Tell [3]:用一个 LSTM 同时编码图像和文本,先输入图像特征,后输入文本单词。LSTM 的最后一个状态作为表征;
- Attribute as Operator [4]:将文本编码为转移矩阵,并应用到图像特征上得到组合特征;
- Parameter hashing [2]:已被编码的文本特征被散列为变换矩阵,用于替代 CNN 网络中的全连接层,以得到组合特征;
- Relationship [1]:首先使用 CNN 提取图像的 2d 特征图(feature map),然后创建一组关系特征,每个特征是 2d 特征图中的 2 个局部特征与文本特征的拼接。这组特征被传入一个 MLP 中并将输出平均化以得到组合特征;
- FiLM [5]:文本特征被用于预测调制特征(modulation features) $\gamma^{i}, \beta^{i} \in \mathbb{R}^{C}$,其中 $i$ 为层的索引(index),$C$ 为特征的数量。之后执行图像特征的仿射变换:$\phi_{x t}^{i}=\gamma^{i} \cdot \phi_{x}^{i}+\beta^{i}$。
其中,本文提出的 TIRG 与 FiLM 的区别在于:
- TIRG 使用非线性变换(而非 FiLM 中的线性变换),具有更多可学习参数,使得能够对图像进行较为复杂的修改;
- TIRG 只修改单层的 CNN。修改尽可能少的层有助于确保修改的特征处于目标图像的相同空间中。
方法
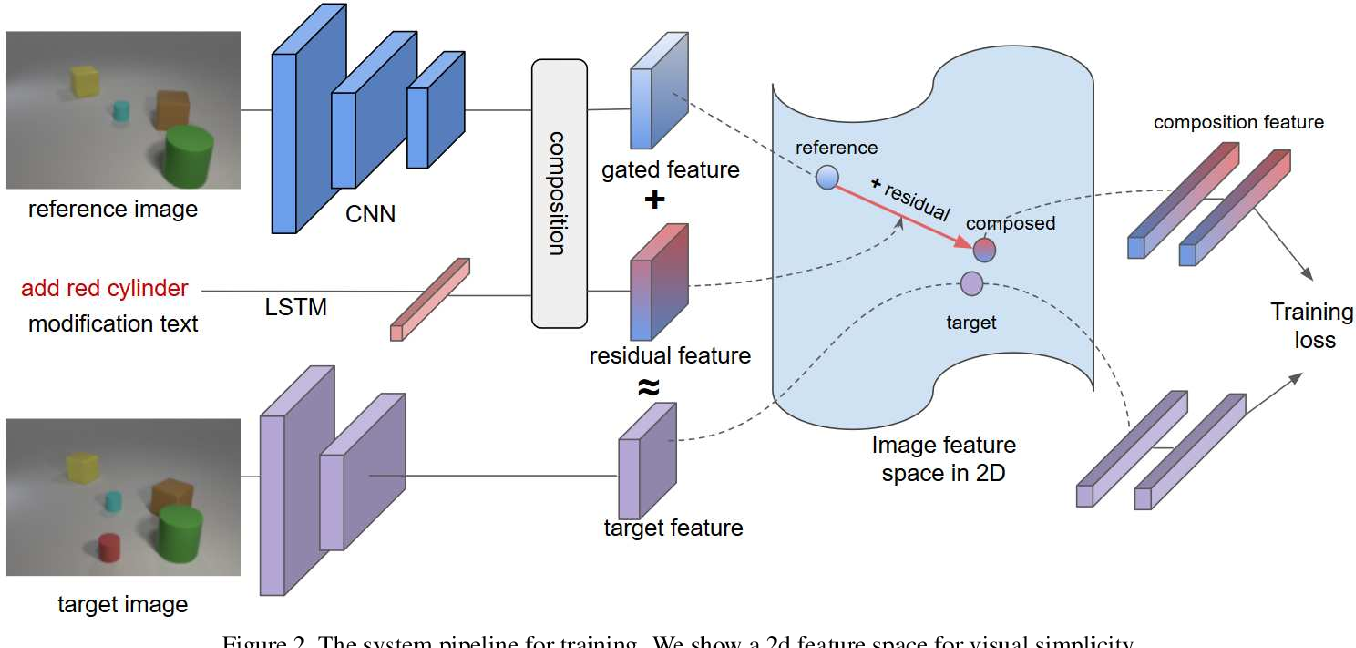
TIRG 的公式为:
$$
\phi_{x t}^{r g}=w_{g} f_{\mathrm{gate}}\left(\phi_{x}, \phi_{t}\right)+w_{r} f_{\mathrm{res}}\left(\phi_{x}, \phi_{t}\right)
$$
其中,$\phi_{x}$ 是 CNN 得到的查询图像特征,$\phi_{t}$ 是 LSTM 得到的文本特征;$f_{\text {gate }}, f_{\text {res }} \in \mathbb{R}^{W \times H \times C}$;$w_{g}, w_{r}$ 是用于平衡的可学习权重。
门控机制的计算为:
$$
f_{\text {gate }}\left(\phi_{x}, \phi_{t}\right)=\sigma\left(W_{g 2} * {RELU}\left(W_{g 1} *\left[\phi_{x}, \phi_{t}\right]\right) \odot \phi_{x}\right.
$$
其中,$W_{g 1}$ 和 $W_{g 2}$ 都是 3x3 卷积核。$\phi_{t}$ 将沿着高度和宽度的尺寸广播(broadcast along the height and width dimension),使其形状与图像特征 $\phi_{x}$ 匹配。
残差连接的计算为:
$$
f_{\text {res }}\left(\phi_{x}, \phi_{t}\right)=W_{r 2} * {RELU}\left(W_{r 1} *\left(\left[\phi_{x}, \phi_{t}\right]\right)\right)
$$
TIRG 的直观理解是我们只想根据文本特征“修改”图像特征,而不是创建一个完全不同的特征空间。门控机制被设计成保留某些与文本修改无关的查询图像特征。
训练方法
训练目标是使“修改后”的图像特征与目标图像特征尽可能接近,同时使与非目标图像特征尽可能远离。因此,采用每次采样一个正例和 B 个负例计算损失,并重复 M 次,公式为:
$$
L=\frac{-1}{M B} \sum_{i=1}^{B} \sum_{m=1}^{M} \log \left\{\frac{\exp \left\{\kappa\left(\psi_{i}, \phi_{i}^{+}\right)\right\}}{\sum_{\phi_{j} \in \mathcal{N}_{i}^{m}} \exp \left\{\kappa\left(\psi_{i}, \phi_{j}\right)\right\}}\right\}
$$
其中 $\kappa$ 是相似度计算函数,在实现中采用点积或负欧式距离(为负时越小的距离能够获得更高的分数)。
实验
对比实验
在三个数据集上进行实验:Fashion200k [6],MIT-States [7],本文提出的 CSS 数据集。三个数据集的区别在于,前两个数据集图像中物体不变,属性之一发生变化;而 CSS 数据集的变化更加复杂,可以增加、减少处于某个位置的物体,也可以改变物体的属性;前两个数据集的图像内容较为丰富,而 CSS 数据集的图像是生成的规律几何体摆放,且有 2D 和 3D 两种图像。
主要评价指标为 recall at rank k (R@K),即正确的图像(即标签)在前 K 个检索出的图像中的百分比。MIT-States 同时汇报分类结果。本文提出的 TIRG 均达到 SOTA。
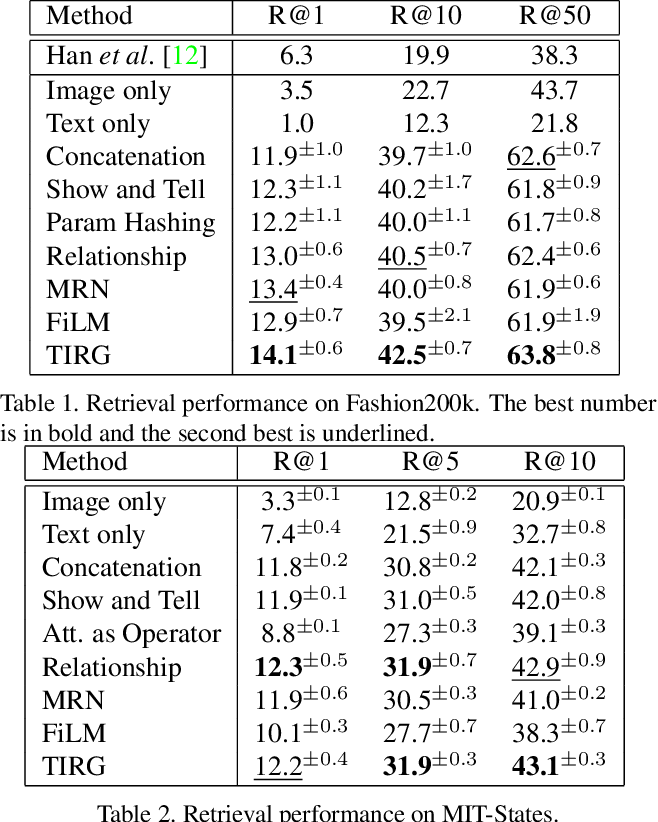
在 Fashion200k 和 MIT-States 数据集上的检索结果如下:
在 MIT-States 数据集上的分类结果如下:

在 CSS 数据集上的检索结果如下:

从组合特征中重建图像

为了更深入地了解组合特征的本质,本文训练了一个转置卷积网络(transposed convolutional network),学习从查询图像的特征中重建图像,然后将其应用于组合特征。对比直接拼接、FiLM 和本文的 TIRG 三种方法得到的组合特征的重建图像。从 TIRG 特征表示生成的图像看起来更好,并且更接近目标图像。
消融实验
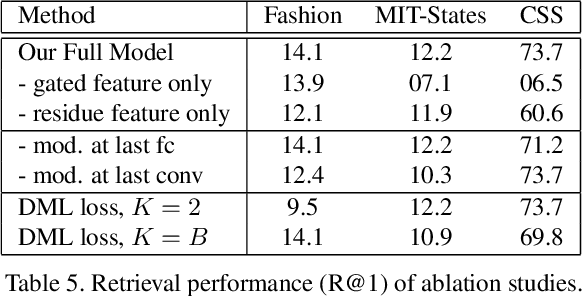
- 去除残差连接和门控机制都会使模型表现显著变差;
- TIRG 的特征修改可发生在最后一个卷积层或最后一个全连接层。实验表明,对于 Fashion200k 和 MIT-States 数据集在最后一个全连接层进行特征修改,以及对于 CSS 数据集在最后一个卷积层进行特征修改,效果更好。作者认为这是因为在 CSS 数据集上的修改更加空间局部化,而在其他两个数据集上的修改更加全局化;
- 设置训练时的每次采样的样本数量为 2(即损失变为 soft triplet loss)或 B(即实验中原本的设置)。当采样大小为 2 时,会发现对于 Fashion200k 这样较大的数据集,网络会欠拟合;而当采样大小为 B 时,网络对 Fashion200k 数据集拟合更好并得到更好的结果,但是对于其他两个数据集训练变得不稳定。
个人笔记
实现
实现预训练的 CNN 和 LSTM
CNN:
1 | import torchvision |
LSTM:
源码自己实现了一个应用于文本的 LSTM,详见 text_model.py。
实现可学习权重 w_g,w_r
通过torch.nn.Parameter将张量添加到参数列表中:
1 | self.a = torch.nn.Parameter(torch.tensor([1.0, 10.0, 1.0, 1.0])) |
将文本特征沿着高度和宽度的尺寸广播后与图像特征拼接
1 | y = text_features |
实现在最后一个卷积层修改特征
1 | class TIRGLastConv(ImgEncoderTextEncoderBase): |
参考论文
- [1] A simple neural network module for relational reasoning, NIPS 2017.
- [2] Image question answering using convolutional neural network with dynamic parameter prediction, CVPR 2016.
- [3] Show and tell: A neural image caption generator, CVPR 2015.
- [4] Attributes as operators, 2018.
- [5] Film: Visual reasoning with a general conditioning layer, 2018.
- [6] Automatic spatially-aware fashion concept discovery, ICCV 2017.
- [7] Discovering states and transformations in image collections, CVPR 2015.