初探人工智能
一篇人工智能及相关概念(机器学习、深度学习、神经网络)的入门知识笔记。带一点点自己的思考。
为什么
为什么作为一个前端学习者,我要对看似毫无关联的人工智能有所了解并进行学习?
- 发挥科班优势。众所周知,机器学习等技术对数学的要求较高,对计算机组织与体系结构、操作系统等计算机基础知识也有一定要求。作为一个就读软件工程的本科生(而且还打算读研),应该充分利用自己的优势来规划职业生涯。
- 随着人工智能的飞速发展,即使是前端也可能与之发生密切的联系。目前相关方面和前端联系的最深的应该就是数据的挖掘及可视化。即使不如此,作为一名软件工程师,也应该要对最前沿的技术有所了解。
- 确实很有意思啊,科幻小说里的人工智能什么的。自己也有时以此为基础构思一些小说的点子。个人感觉,真正的人工智能确实是会对人类的未来造成巨大影响的事物。
何况,我手上还有一本蔡恒进老师的《机器崛起前传——自我意识与人类智慧的开端》没读,带签名的。既然蔡老师赠给我了,还是要抽时间读一读的。
这不代表我放弃了前端的学习。在静下心来巩固 JavaScript 基础的同时,我希望自己学会放宽视野,在 20 岁之前。
不要拒绝未来的任何可能性。
相关概念脑图
一直感觉纯文字的笔记比较难以记忆,导致自己的学习吸收率不高。看到别人的读书笔记是总结了一张脑图,条理比较清晰。这里也试着用 Xmind 总结一张相关概念的脑图(P.S.使用感觉百度脑图比 Xmind 条理清晰+好用)。

数据
学习算法的输入数据,叫“训练数据”。训练数据的每一行称为一个“训练样本”(Training Sample),通常简称“样本”(Sample)。
样本的各种属性称为“特征”(Feature)。而希望学得的模型可以用来预判的信息称为样本的“标注”(Label)。
模型
机器学到的模型是一个映射。
映射的输入
每个样本 xi 的特征组成一个**“特征向量” (Feature Vector)。所有特征向量的集合就是总的输入集合,称为“样本空间” (Sample Space)**。
映射的输出
第 i 个样本的标注记作 yi。同理有**“标注空间”(Label Space)**。
映射的表示
机器学习模型就是输入空间 X 到输出空间 Y 的一个映射,将映射用符号 g 表示,则模型记作 g: X -> Y。
机器学习
学习算法 (Learning Algorithm) 根据训练数据,从**假设集合 (Hypothesis Set) **中选出最优的那个映射 g 作为最终学得的模型,使得 g 越接近上帝真相 f 越好。
分类
不是所有的机器学习问题都需要标注。根据训练数据是否有标注,机器学习问题大致划分为监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)两大类(还有半监督学习、增强学习等)。
- 监督学习:每个输入样本都有标注。大致分成两类:
- 分类(Classification)问题:标注是离散值,比如用户”点击“和”不点击“。如果标注只有两个值,则称为二分类,如果标注有多个值,则称为多分类。
- 回归(Regression)问题:标注是连续值,比如如果问题是预测北京市房屋的价格,价格作为标注就是一个连续值,属于回归问题。
- 无监督学习:训练样本不需要标注。这类模型试图学习或是提取数据背后的结构,或从中抽取最为重要的特征。无监督学习解决的典型问题是聚类(clustering)问题,比如对一个网站的用户进行聚类,根据用户特征进行分组,看看这个网站用户的大致构成,分析下每类用户群的特点是什么。
以上总结为脑图:

神经网络
把听上去最高端的“神经网络”放到最后介绍。
神经网络
一组大致模仿人类大脑构造设计的算法,用于识别模式。神经网络通过机器感知系统解释传感器数据,能够对原始输入进行标记或聚类等操作。
神经网络所能识别的模式是数值形式,因此图像、声音、文本、时间序列等一切现实世界的数据必须转换为数值。
感知器、权重与阈值
大家都在高中的生物课上学过,人类大脑思考的基础是神经元(神经细胞)。如果能够人工制造神经元,就能组成人工神经网络来模拟思考。
上世纪六十年代,科学家们提出了最早的“人造神经元”,并将其称为“感知器”(perceptron)。感知器接受一些因素,这些因素根据不同的重要性(决定性因素与次要因素)获得不同的权重(weight)。因素的条件成立为 1,不成立为 0,乘以权重的总和大于指定的阈值(threshold),感知器便输出 11,否则输出 0。
决策模型
单个的感知器构成一个简单的决策模型。而实际的决策模型是由多个感知器组成的多层网络。
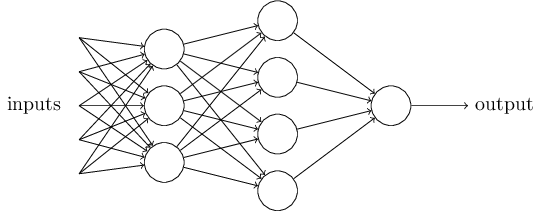
每一个节点层在前一层输出的基础上学习识别一组特定的特征。随着神经网络深度增加,节点所能识别的特征也就越来越复杂,因为每一层会整合并重组前一层的特征。
而在“递归神经网络”中,上下层的感知器的输入与输出还可能发生循环传递。
神经网络运作过程
一个神经网络的搭建,需要满足三个条件:
- 输入和输出
- 权重(w)和阈值(b)
- 多层感知器的结构
最困难的部分就是确定权重和阈值。我们通过试错法,即保证其他参数不变,对 w 或 b 进行微小变动,然后观察输出的变化。通过不断重复这个过程来得到最精确的那组 w 和 b。这个过程即被称为模型的训练。
因此,神经网络的运作过程如下:
- 确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算 w 和 b
- 一旦新的数据产生,输入模型,就可以得到结果,同时对 w 和 b 进行校正
整个过程需要海量计算,所以需要使用专门为机器学习定制的 GPU。
输出的连续性
为了保证模型的敏感,要将 0、1 输出改造为连续性函数。
1 | z = wx + b |
这样,当 z 趋向正无穷(表示感知器强烈匹配)时,σ(z) → 1;如果 z 趋向负无穷(表示感知器强烈不匹配),σ(z) → 0。
同时,Δσ 满足下面的公式:
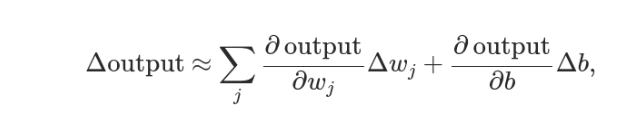
即 Δσ 和 Δw 和 Δb 之间是线性关系,变化率是偏导数。这就有利于精确推算出 w 和 b 的值了。
基于 JavaScript 的机器学习
尽管确实是第一选择,机器学习不一定要用 Python。为什么不试试神奇的 JavaScript 呢?
JavaScript 开发者们已经开源了不少基于 Node.js 的机器学习库:
- brain.js (神经网络)
- Synaptic (神经网络)
- Natural (自然语言处理)
- ConvNetJS (卷积神经网络)
- mljs (一系列具有多个函数方法的 AI 库)
- Neataptic (神经网络)
- Webdnn (深度学习)
你可以从 github 的这个项目:abhisheksoni27/machine-learning-with-js 中获得一些实例的源码,目前作者实现了线性规划和 KNN 算法。你也可以在参考资料的对应章节找到翻译版本进行阅读。
结语
emmm,如果你看了之后的参考资料中的每一篇,你会发现这篇博文只是一个拙劣的归纳总结。这是因为我确实对相关领域没有什么了解。但我对此兴致勃勃,也已经关注了不少数据挖掘和机器学习的知乎专栏及收藏夹。希望自己将来会有相关方面有价值的产出。
参考资料
相关概念部分
数据、模型部分
神经网络部分
基于 JavaScript 的机器学习
扩展学习
- 神经网络浅讲:从神经元到深度学习
- 机器学习算法的基本知识(使用Python和R代码):带有 Python 和 R 语言代码实例
- Deep Learning 中文翻译
- [机器学习]机器学习笔记整理全解
- DT新纪元 - 知乎专栏