
Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024)
arXiv github poster (CVPR 2024) poster (VALSE 2024)
Background
Recent compositional zero-shot learning (CZSL) methods adapt pre-trained vision-language models (VLMs) by constructing trainable prompts only for composed state-object pairs. Relying on learning the joint representation of seen compositions, these methods ignore the explicit modeling of the state and object, thus limiting the exploitation of pre-trained knowledge and generalization to unseen compositions. In this paper, our contributions are:
-
We propose a novel Multi-Path paradigm for CZSL with VLMs, which explicitly constructs vision-language alignments for the state, object, and composition. The paradigm is flexible enough to derive new approaches.
-
Based on the paradigm, we implement a model named Troika that effectively aligns the branch-specific prompt representations and decomposed visual features.
-
We further design a Cross-Modal Traction module for Troika that adaptively adjusts the prompt representation depending on the visual content.
-
We conduct extensive experiments on three CZSL benchmark datasets to show that Troika achieves the SOTA performance on both closed-world and open-world settings.
Generalizing in Multi-Path Paradigm
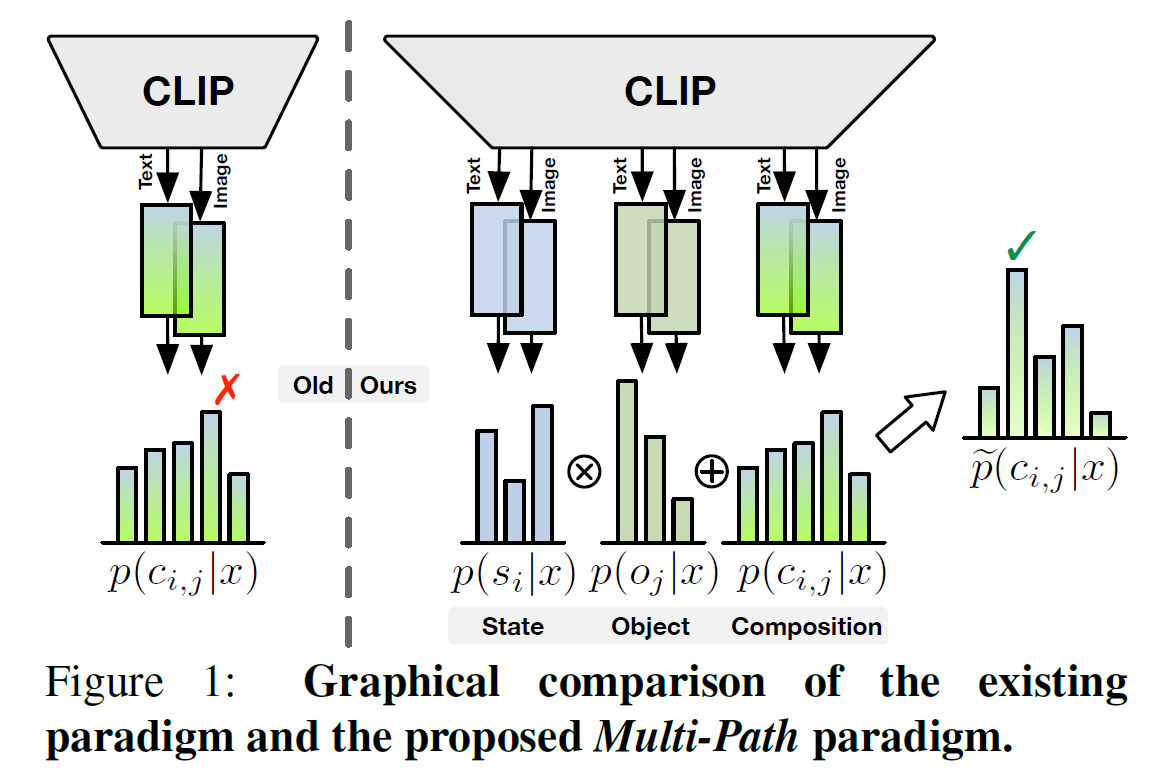
Crucially, our proposed Multi-Path paradigm requires a recognition branch for each of the three semantic components, i.e., state, object, and composition. These branches are essentially cross-modal alignments that independently unearth specific knowledge from large-scale vision-language pre-training. Specifically, during training, three branches can collectively optimize the parameters in a multi-task learning manner. And for inference, the prediction results of state and object can be incorporated to assist the composition branch, thereby mitigating the excessive bias towards seen compositions. Without further implementation constraints, the flexibility of the \MP paradigm allows for the derivation of new methods, which can freely exploit various multi-modal features extracted by the powerful VLMs.
Troika: Our Implementation
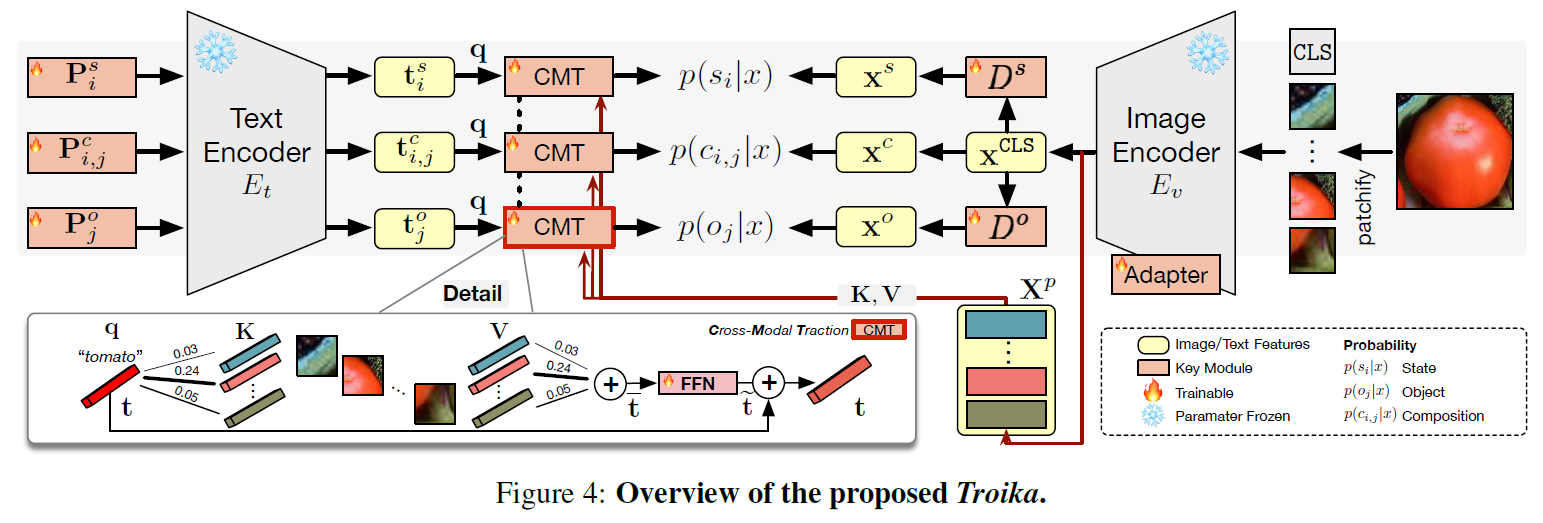
Instantiations

Learning Prompt Representations. As the semantic roles of the target classes on each branch are different, it is natural to introduce different priors through special contexts. Therefore, while maintaining the same primitive vocabulary as a cue of semantic compositionality, we employ an independent prompt prefix for each branch of Troika. The constructed fully trainable prompts are then fed into the text encoder to obtain the prompt representation for each branch.
Learning Visual Representations. While existing methods directly apply the frozen image encoder, we first introduce Adapter to adapt the image encoder without updating its original parameters. Then, to establish cross-modal alignment on each branch, specific visual features for the composition, state, and object should be extracted. Still treating the image representation as the composition visual representation, we introduce the state disentangler and object disentangler, implemented with two individual MLPs, to decompose the state and object visual features.
Training. In each branch, the cross-entropy loss encourages the model to explicitly recognize the corresponding semantic role. And weighting coefficients balance the influences of different losses in the overall training loss.
Inference. During inference, the primitive predictions are combined to complement the composition prediction, thus promoting a more robust recognition system.
Cross-Modal Traction
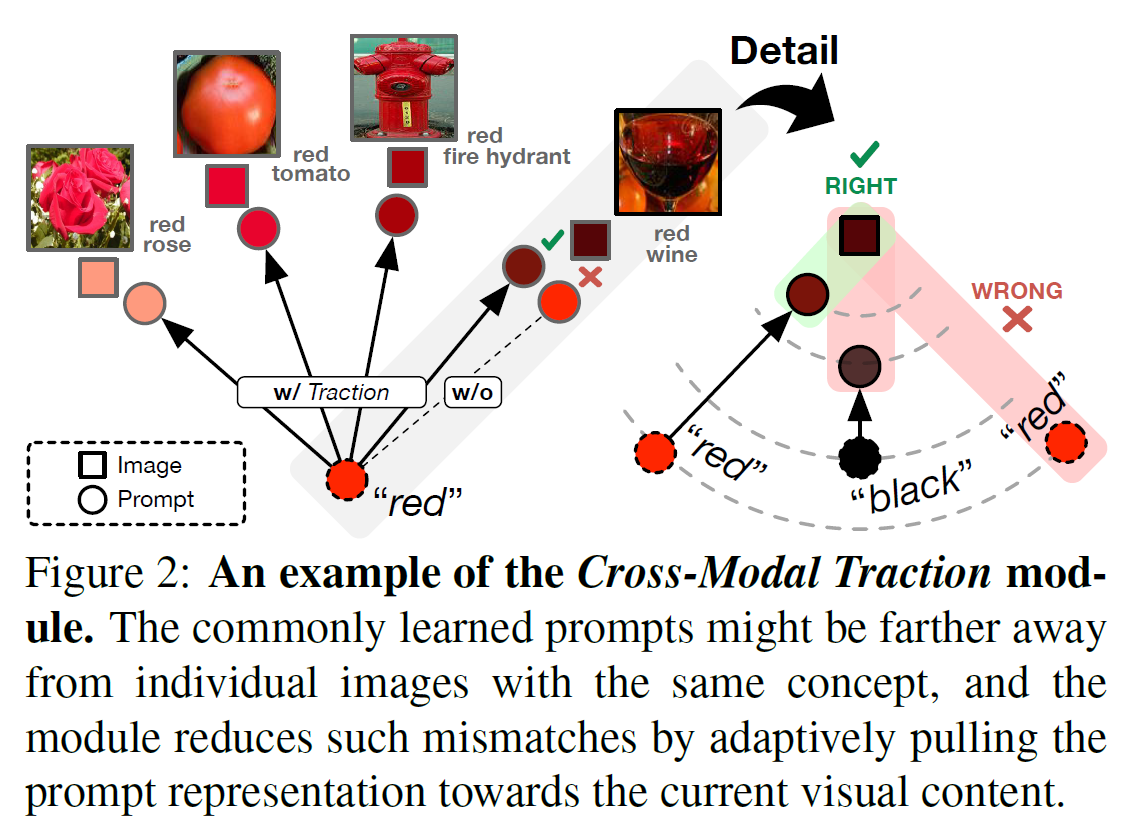
Although inheriting the rich cross-modal understanding of VLMs, discrepancies may still exist between semantically similar vision-language representations. Given the same semantic concept, the static and monotonous prompt representation naturally fails to be commonly optimal for all input images that come from a plentiful distribution. This issue becomes more serious in the additional state and object branches, as the visual content of the same primitive changes considerably when paired with different primitives. Therefore, we further develop a Cross-Modal Traction module for Troika. The module adaptively shifts the prompt representation to accommodate the content diversity and diminish the cross-modal discrepancies. In this process, relevant patch features serve as the guidance to avoid noise from semantic-agnostic sub-regions interfering with the traction.
Experiment Results
Here we report some experimental results to empirically show the effectiveness of our Troika. Please check the paper for the details of the experiment settings and further analysis.
Main Results
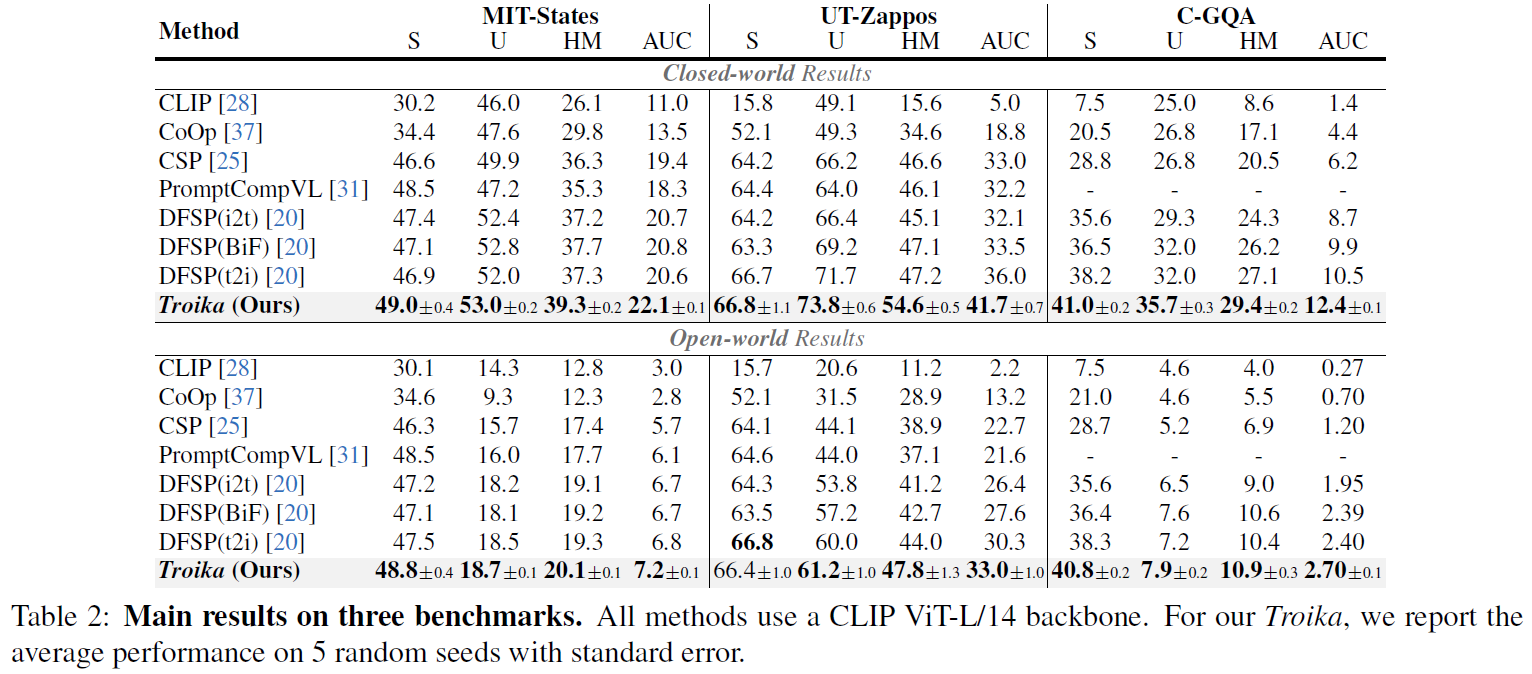
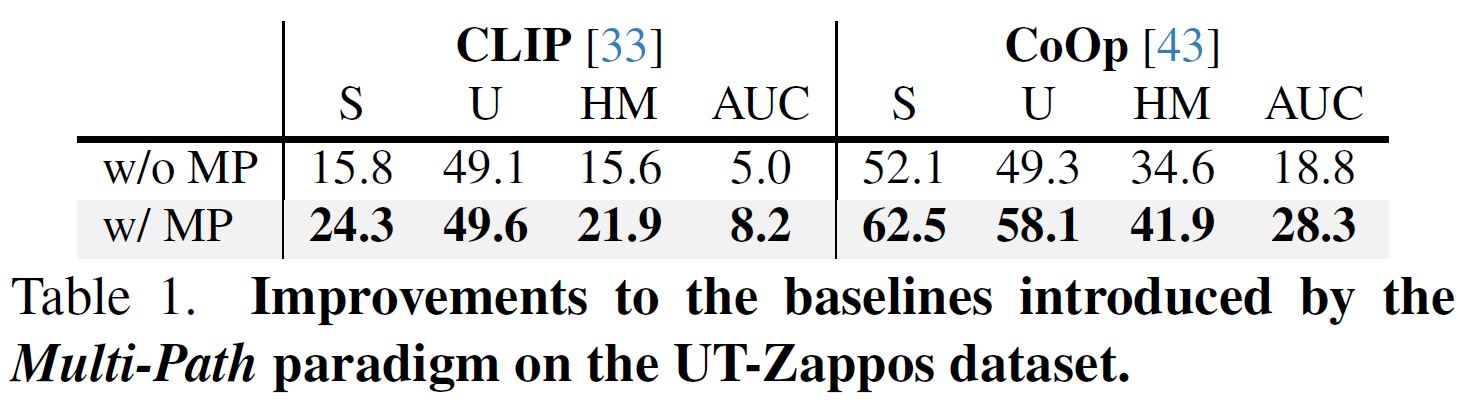
The above results are obtained with a pre-trained CLIP (ViT-L/14). More experimental results can be found in the paper.
Qualitative Results

We report the predictions of the complete Troika and the models that remove the Multi-Path paradigm or the Cross-Modal Traction module. Benefiting from both two innovations, Troika recognizes the compositions with higher accuracy. Taking the 5th case in the top row as an example, while the incomplete methods may be confused by the color and material presented by the object, the complete Troika can focus on details such as shape, surface texture, and even local regions containing lens for comprehensive reasoning.
We also show some failure cases, where the entanglement of visual features places extreme demands on combinatorial understanding. However, the proposed Multi-Path paradigm enables the complete Troika to correctly identify part of the contained primitives. For the cases of complete prediction errors, although different from the provided labels, we find that the predictions can also interpret the content of these images. This indicates the effectiveness of our Troika from another perspective beyond the metrics.
BibTex
If you find this work useful in your research, please cite our paper:
@inproceedings{Huang2024Troika,
title={Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning},
author={Siteng Huang and Biao Gong and Yutong Feng and Yiliang Lv and Donglin Wang},
booktitle = {Proceedings of the {IEEE/CVF} Conference on Computer Vision and Pattern Recognition 2024},
month = {June},
year = {2024}
}