
VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (CVPR 2023)
arXiv github video (Youtube) poster slide ModelScope
Background

Many recent studies leverage the pre-trained CLIP for text-video cross-modal retrieval by tuning the backbone with additional heavy modules, which not only brings huge computational burdens with much more parameters, but also leads to the knowledge forgetting from upstream models. In this paper, we continue the vein of prompt tuning to transfer pre-trained CLIP for text-video retrieval with both effectiveness and efficiency. Main contributions are:
-
We propose the VoP as a strong baseline that effectively adapts CLIP to text-video retrieval with only 0.1% trainable parameters.
-
To exploit video-specific information, we further develop three video prompts respectively conditioned on the frame position, frame context, and layer function. To the best of our knowledge, this is the first work that explores video-specific prompts.
-
Extensive experiments on five text-video retrieval benchmarks demonstrate that various combinations of our video prompts effectively enhance VoP, achieving at most 1.4% average relative improvement with much fewer trainable parameters compared to full fine-tuning.
Model Overview
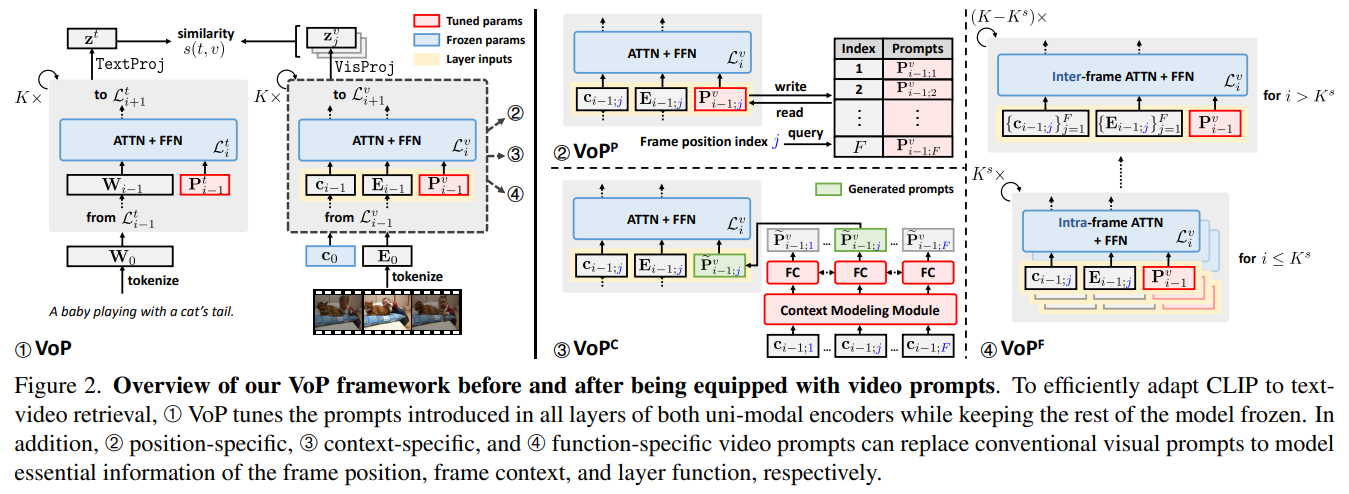
We propose the VoP: Text-Video Co-operative Prompt Tuning to simultaneously introduce tunable prompts in both textual and visual encoders. Also, different from existing related efforts that only insert prompt vectors into the input textual sequences, we find that preparing prompts for every layer of both encoders can further close the gap to full fine-tuning. To exploit essential video-specific information, we further design three novel video prompts from different perspectives, which can seamlessly replace conventional visual prompts in VoP. Specifically,
- position-specific video prompts model the information shared between frames at the same relative position.
- Generated context-specific video prompts integrate injected contextual message from the frame sequence into the intra-frame modeling.
- And function-specific video prompts adaptively assist to learn intra- or inter-frame affinities by sensing the transformation of layer functions.
By exploring video-specific prompts, VoP offers a new way to transfer pre-trained foundation models to the downstream video domain.
Experiment Results
Here we report some experimental results to empirically show the effectiveness and efficiency of our VoP series. Please check the paper for the details of the experiment settings and further analysis.
Main Results
The following results are obtained with a pre-trained CLIP (ViT-B/32). More experimental results can be found in the paper.
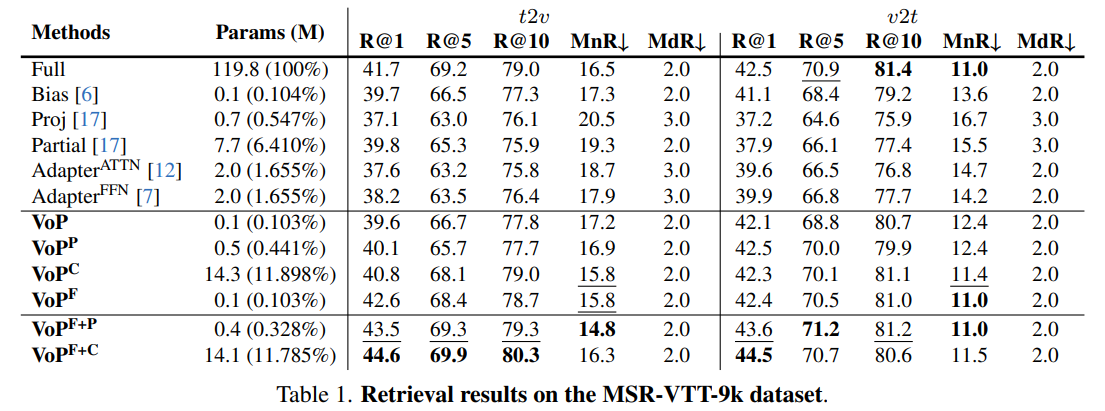
t2v and v2t retrieval results on MSR-VTT-9k dataset:
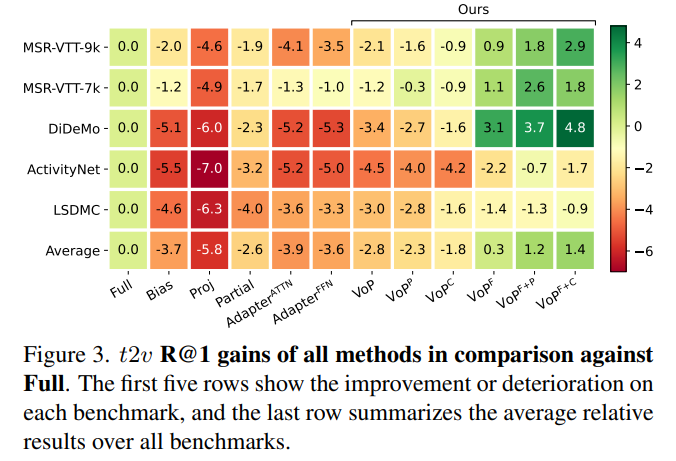
t2v relative results on all datasets:
Qualitative Results

- In the top left example, Full and our proposed methods can retrieve the correct video while Partial matches an unrelated one, which shows the inferiority of existing efficient tuning protocols.
- In the top right example, Full fails to recognize a “Japanese” book while parameter-efficient tuning methods succeed by capturing visual clues of Japanese characters and related English words like “Tokyo”, indicating that updating all parameters might be an unsatisfactory strategy as more knowledge from large-scale text-image pre-training is forgotten.
- In the bottom left example, by fine-tuning all parameters with video datasets or designing specialized prompting solutions for videos, Full and VoPF+C can understand the whole event represented by sequenced frames. Even if some textual elements like “priest” are not visually present, the methods overcome such minor semantic misalignments and select more relevant candidates from a global view.
- In the bottom right example, understanding the concept of “tail” and capturing the interaction of “playing with”, VoPF+C can distinguish the correct video from hard negative candidates while all the other three methods fail.
BibTex
If you find this work useful in your research, please cite our paper:
@inproceedings{Huang2023VoP,
title={VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval},
author={Siteng Huang and Biao Gong and Yulin Pan and Jianwen Jiang and Yiliang Lv and Yuyuan Li and Donglin Wang},
booktitle = {Proceedings of the {IEEE/CVF} Conference on Computer Vision and Pattern Recognition 2023},
month = {June},
year = {2023}
}