【paper reading】ICLR 2021 论文选读
这篇博文简单记录一下我快速阅读 ICLR 2021 其中一些我感兴趣的论文时的笔记和感想等。由于论文数量比较多,因此可能后续还会更新。接收列表见 Paper Digest: ICLR 2021 Highlights。
我比较关注的 topic 包括 transfer learning 下的 few-shot learning、domain adaptation、domain generalization 等,以及包括 VQA、visual grounding 在内的一些多模态学习的任务。我用 “#topic” 来标明这篇论文所属的 topic,这样既不用生硬地将属于多个 topic 的论文强行归类到单一 topic 下,也方便各位读者在页面内用 CTRL+F 来搜索自己感兴趣的 topic。
Few-shot Learning
- Wandering Within A World: Online Contextualized Few-shot Learning
#continual learning #lifelong learning
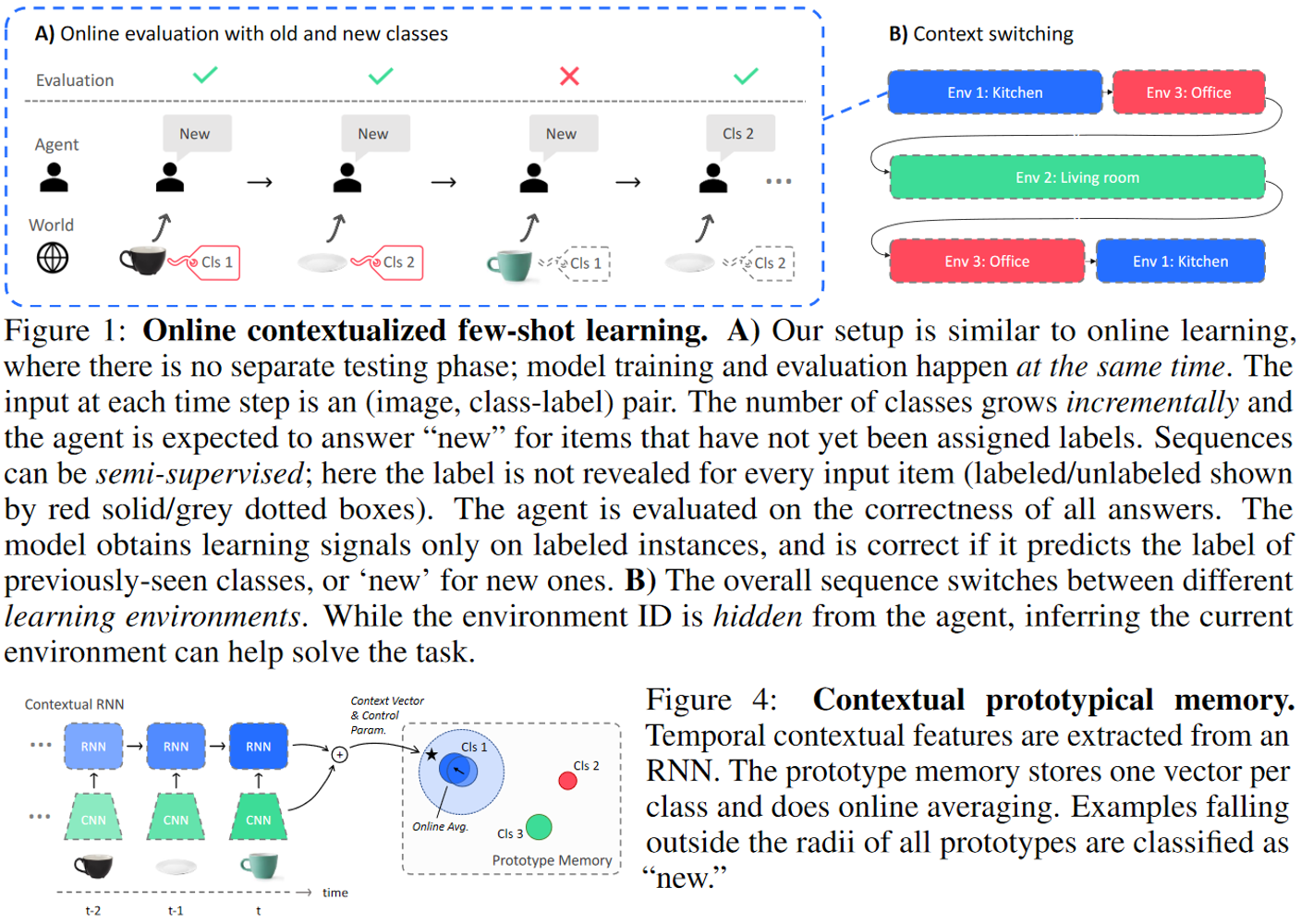
本文提出了一种新的学习范式 online contextualized few-shot learning,要求模型考虑上下文切换来进行在线的小样本学习。同时,本文提出 contextual prototypical memory(CPM)模型,通过集成 RNN 来编码上下文信息,并且有一个独立的原型存储(prototype memory)来记住已经学过的类别,在所有原型半径外的样本会被预测为新类。该模型在本文构建的三个数据集上能够比扩展后的经典 FSL 算法表现更好。
- Free Lunch for Few-shot Learning: Distribution Calibration
#data augmentation
对于每个 support sample,寻找 base classes 中原型与其最相似的 k 个类别,用这些类的均值和协方差来同该 support sample 一起得到新的均值和协方差作为分布的参数,从而通过从该分布中采样来进行特征级别的数据增强。
- A Universal Representation Transformer Layer for Few-Shot Image Classification
#cross-domain #self-attention #metric-based
![]()
本文提出了多头的泛用表征转换层(multi-head universal representation transformer layer),在 Meta-Dataset 上表现良好。在单头 URT 层中,对于每个域有一个预训练好的特征提取器,模型对各类原型进行自注意力计算。query 是每个类 $c$ 的原型经线性层的产物 $q_c$,key 是每个域 $i$ 的特征提取器得到的每个类 $c$ 的原型经线性层的产物 $k_{i, c}$。计算得到的权重求平均得到每个域的权重,和对应特征提取器的特征得到调整后的表征。多头 URT 层将单头 URT 层得到的表征拼接,以用于原型分类等。
- Concept Learners for Few-Shot Learning
#compositionality #auxiliary semantic #metric-based
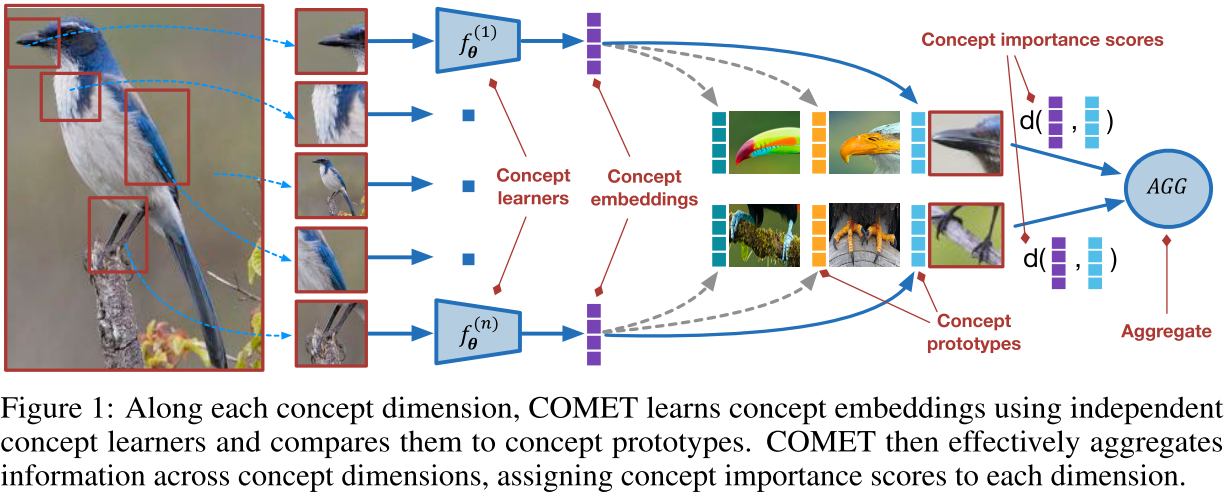
本文使用了额外的辅助模态,以向量的形式来表现图像中包含的概念。每个概念有一个对应的特征提取器(即卷积骨干网络,实验中分为参数共享和不共享两种),概念向量与样本进行点积后过该特征提取器来得到概念特定的特征,最后进行原型分类的距离就是查询样本的概念特定特征和支持样本的概念特定原型间的欧氏距离对于所有概念的总和。这些概念也可以通过已有的 landmark discovery 方法来无监督式地得到。
提供了特征提取器共享参数的实验结果可以部分消除对参数量大幅增加的质疑,但是在提供有监督概念时只和只用视觉信息的 baselines 比较,我认为是不公平的。
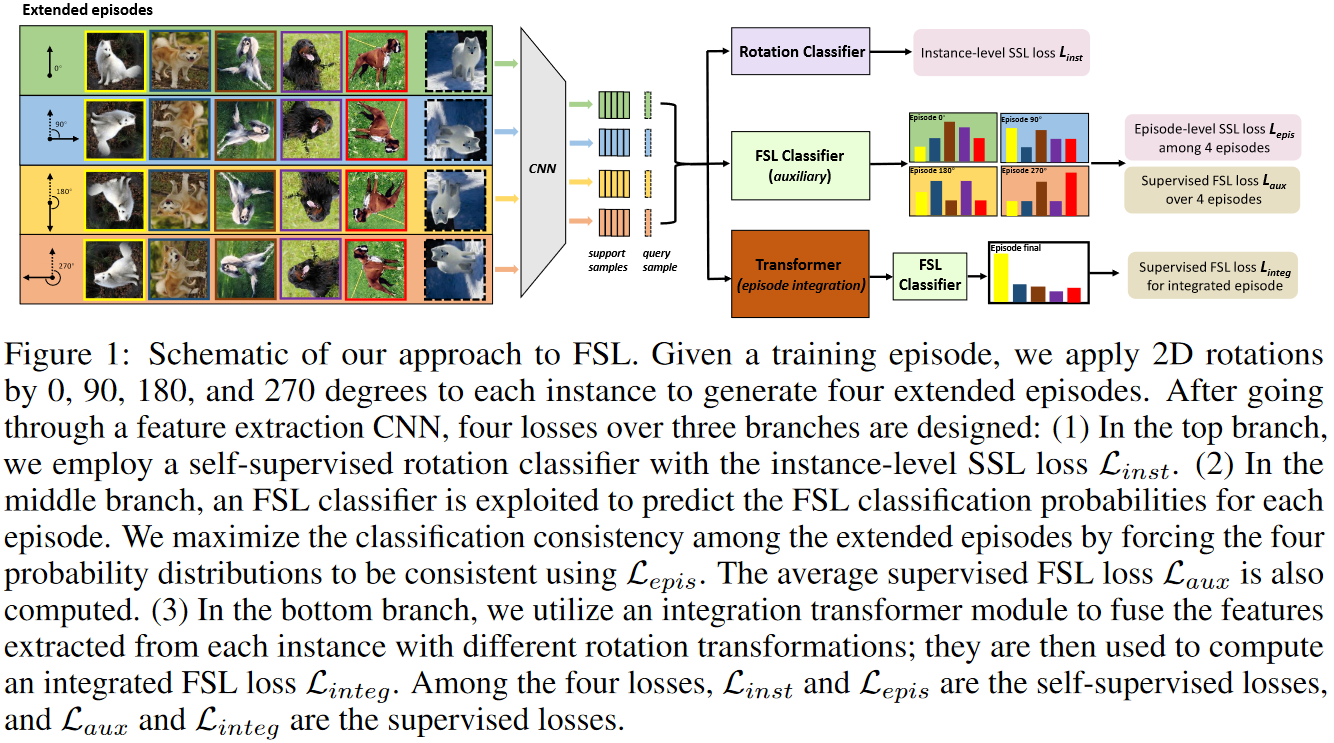
引入旋转预测的自监督任务后,该方法对于每个旋转角度将 episode 内所有支持和查询样本进行对应旋转来得到一个扩展任务。总 loss 由四部分组成:(1) 预测每个旋转后的样本的旋转角度的 loss;(2) 在每个旋转角度对应的扩展任务中,查询样本分类的 loss;(3) 跨所有扩展任务中,同一查询样本对应的预测概率分布的一致性 loss,具体做法是将该样本的各扩展任务中的预测概率分布与所有扩展任务的预测概率分布均值求 KL 散度;(4) 将同一样本在不同旋转角度后得到的特征视为同一序列中的不同 token,进行自注意力计算后拼接来用于分类得到 loss。
- Constellation Nets for Few-Shot Learning
#metric-based #self-attention #compositionality #clustering
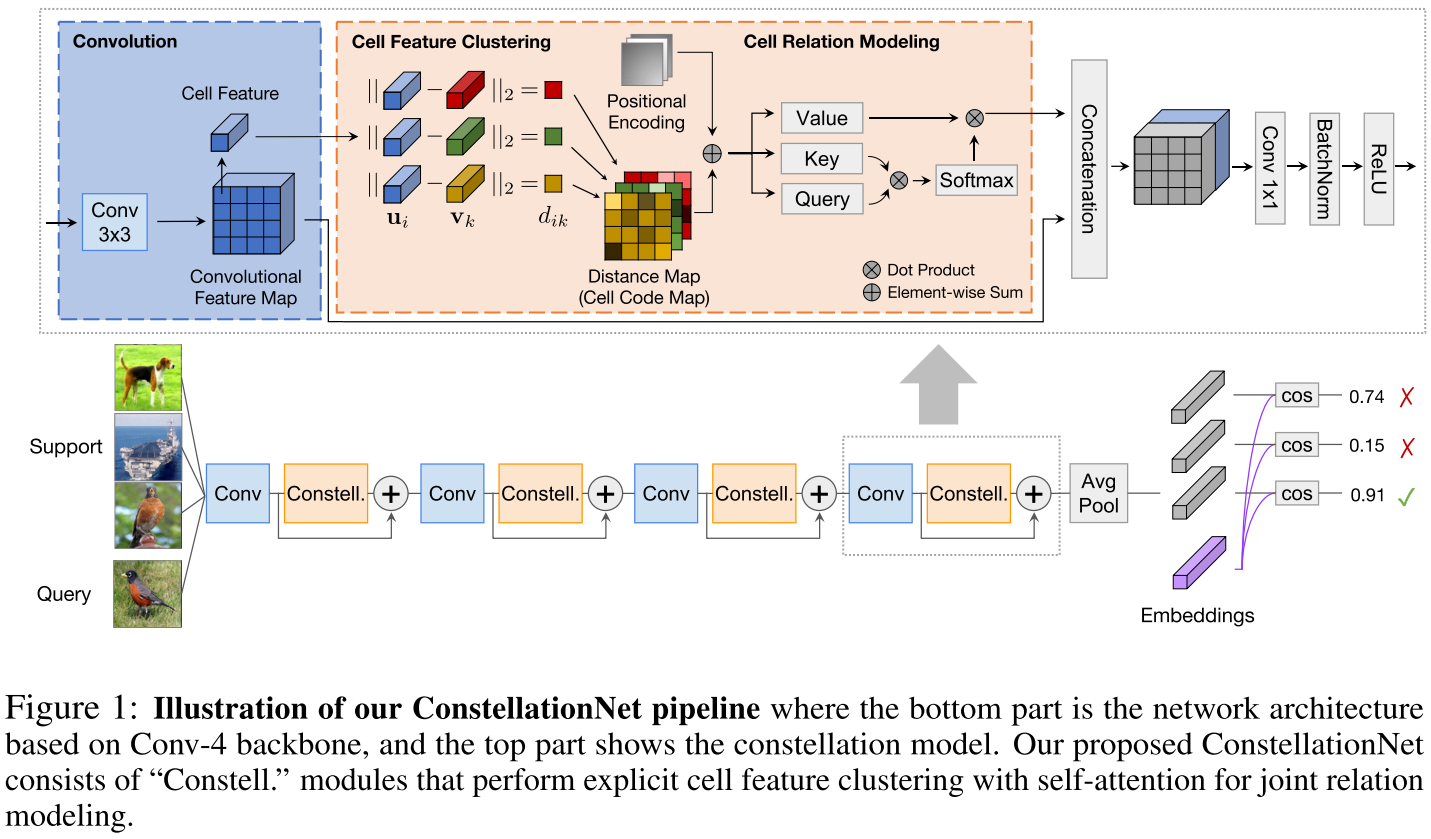
本文将特征图上每个位置的局部特征 $u \in R^C$ 进行软聚类,将所有局部特征到所有聚类中心的距离组织为一张距离图 $D \in R^{B \times H \times W \times K}$,之后再将 $D$ 和一个位置编码 $P \in R^{B \times H \times W \times K}$ 相加来作为 query 和 key、$D$ 作为 value 进行多头自注意力运算。上述运算结果和特征图拼接后过 1x1 卷积,从而在骨干网络的每个卷积层后无缝接入 constellation 模型,以结合隐式和显式的 part-based representations。
- MetaNorm: Learning to Normalize Few-Shot Batches Across Domains
#meta-learning #normalization
本文认为当 batch size 较小或者 distribution shift 较大(训练集的统计数据不适用于测试集)时,batch 的统计数据是不可靠的。因此本文提出一种基于原学习的 batch normaliztion 方法,旨在利用一个神经网络来根据输入的样本生成统计数据来最小化不同 domain 或者 support 和 query 间的 KL 散度。该方法在小样本分类、domain generalization 以及提出的 few-shot domain generalization(meta-train 和 meta-test 每个 episode 中类别不同,每个 episode 内部 support 和 query 的 domain 不同)等任务上普遍优于现有的 normalization 方法。
Meta Learning
- Unsupervised Meta-Learning through Latent-Space Interpolation in Generative Models
#unsupervised learning #generative adversarial networks

现有的无监督元学习方法主要依靠包含聚类、数据增强、随机采样等方法来生成合成任务,这些方法的缺点是根据领域的不同,它们需要较大的调整。本文提出使用现成的、预训练好的生成模型,通过在隐式空间在进行插值来生成合成任务。该方法的优点在于基本不需要根据特定领域进行调整,仅有的一些超参数调整也具有可理解性。
Zero-shot Learning
![]()
本文针对在不重新训练模型的情况下迁移到训练期间不可见的发声者风格的任务,认为现有的基于预训练分割编码器或者 AdaIN 的方法都无法较好地分离风格和内容编码。因此,本文最小化风格和内容编码间基于样本的互信息上界,并且最大化两个新的多组互信息下界来增强编码的表示能力。
DA / DG
- Systematic generalisation with group invariant predictions
#systematic generalisation #invariance penalty #semantic anomaly detection #domain generalization

本文提出,数据集通常存在和目标变量相关的简单特征(但不健壮)以及更加复杂但是健壮的特征。在三个合成的数据集 coloured-MNIST、COCO-on-colours 和 COCO-on-places 上的实验结果表明,用一个 soft-partition predicting network 来将数据集划分为 majority and minority groups,并且对不同 group 同类样本的特征施加不变性惩罚(例如 KL 散度)有助于模型关注这些更加健壮的特征。
Spotlight。本文对不同类型的 shift 的划分还是挺有意思的,感觉和一些在视觉上做因果学习的工作在思路上有共通之处。方法上比较简单,可能这就是大巧不工吧。然后我比较关心的问题包括能否在真实数据集上使用这个方法,效果如何?Reviewer 3 也提出了相同的问题,举例问能否在 ImageNet 上找到一个合适的划分。作者的回答是像 ImageNet 这种数据来源丰富、相对杂乱的数据集可能难度比较大,而像医学图像这种数据来源相对单一的就要好一些。
- In Search of Lost Domain Generalization
#domain generalization #benchmark
本文为 DG 实现了一个名为 DomainBed 的 testbed,包含 7 个数据集、14 种算法和 3 种模型选择策略。结论是 ERM 仍然是一个非常有竞争力的 baseline。
在我看来这篇论文的一大贡献是讨论了不同模型选择策略带来的影响,包括 training-domain validation(将训练数据划分为 train 和 val set)、leave-one-domain-out validation(给定多个训练域,每次将一个域作为 val,将平均准确率作为指标选择出超参后再在所有训练域上重新训练模型)、test-domain validation(允许用非常有限的测试数据来挑选模型。注意这通常不是一个合理的方法)。另一大贡献自然就是这个还挺大的实验规模,以及给后续工作留下一个还不错的 testbed。
- Domain Generalization with MixStyle
#domain generalization

本文受 instance normalization(IN)和 adaptive instance normalization(AdaIN)启发,提出在将样本进行分 domain 打乱或者随机打乱后,用一个随机的权重来混合两个样本的特征统计信息,从而模拟新风格来约束 CNN 的训练。该方法在分类、检索和 RL 上都取得了效果。
- Robust and Generalizable Visual Representation Learning via Random Convolutions
#domain generalization #data augmentation

本文旨在从单源域数据学习和局部纹理和颜色无关的健壮视觉表征,因此提出一种数据增强技术 RandConv,用随机得卷积来生成有随机纹理但是保留全局形状的图像来提升泛化性。
VQA
- Iterated learning for emergent systematicity in VQA
#visual question-answering #modular networks #iterated learning #compositional generalization
神经模块网络(neural module networks, NMN)通常需要一个程序生成器(program generator)来生成符号化的程序将模块组织成计算图。然而,生成的程序很难组合式泛化。本文提出用迭式学习(iterated learning, IL)的方式,将 NMN 的程序看作来自“布局语言”的样本。在本文提出的 SHAPES-SyGet 数据集以及 CLEVR、CLOSURE 上,本方法可以用 1/10 甚至更少的程序标注与 SOTA 相媲美。
Oral。评审的意见主要集中在实验选用的数据集比较 toyish。之后作者补做了在 GQA 数据集上的实验, Vector-NMN+IL 用 4000 个程序标注能够和 Vector-NMN 用 943000 个程序标注的效果持平。
RL
- Ask Your Humans: Using Human Instructions to Improve Generalization in Reinforcement Learning
#reinforcement learning #natural language #imitation learning
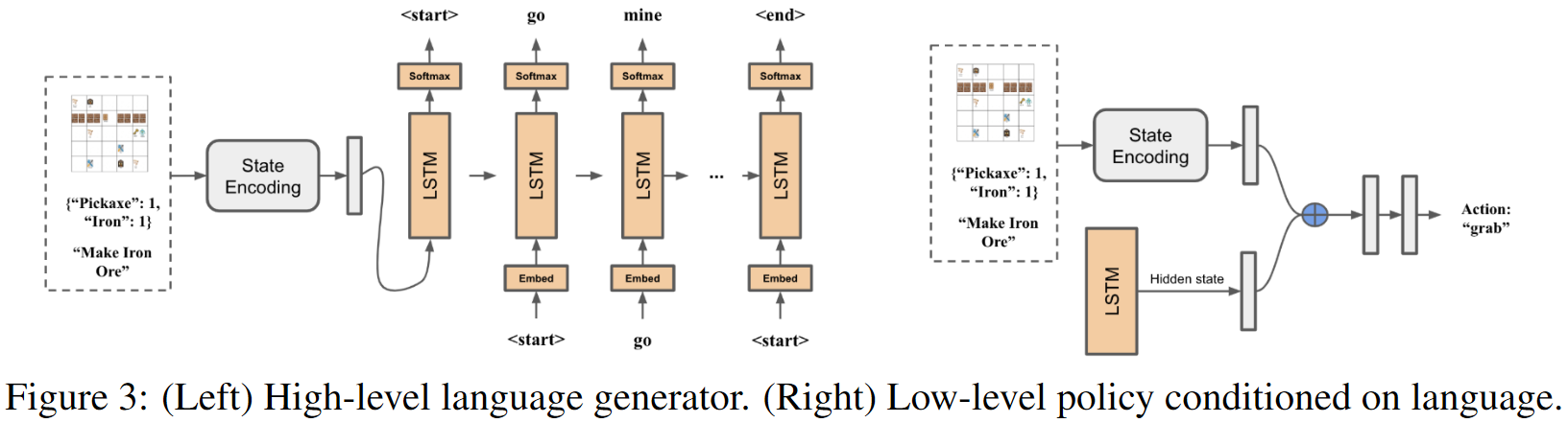
本文引入了一个提供自然语言指令和动作轨迹作为人类演示,一个类似 Minecraft 的 5x5 gridworld 数据集,包括 35 个任务的 6000 条指令。提出的新模型 (1) 在给定状态和目标时,学习为要执行的高级子任务生成自然语言描述;(2) 学习语言控制的低级策略来实际执行这些步骤。模型首先通过模仿学习进行预训练,之后用 RL 的 PPO 算法和稀疏 reward 进行微调(微调过程不使用 ground-truth 语言指令)。实验证明该模型能够在 zero-shot 设置下泛化到不可见任务中生成的自然语言指令,并且提供了可解释的行为。
- Solving Compositional Reinforcement Learning Problems via Task Reduction
#reinforcement learning #imitation learning
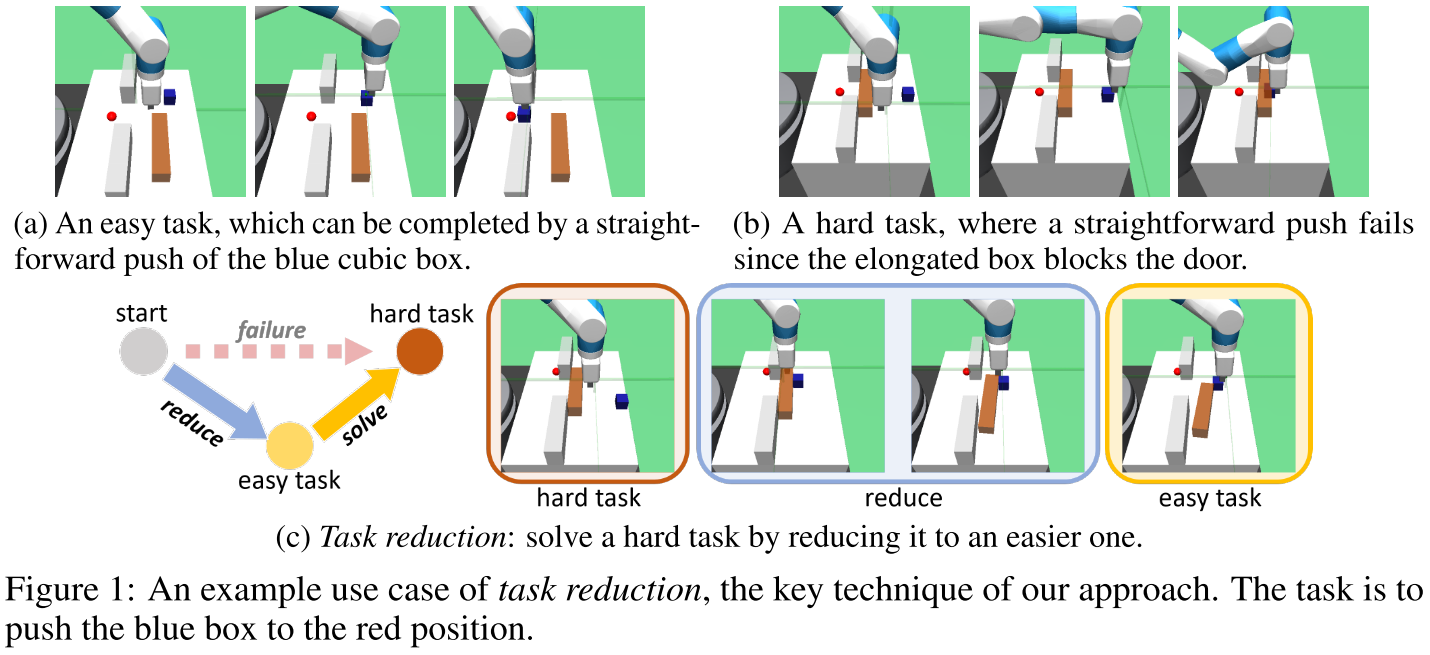
本文提出一种新的学习范式 Self-Imitation via Reduction (SIR) 来解决有稀疏 reward 的组合性持续控制问题。该范式首先将较难的任务简化为解决方案已知的简单任务(称为任务缩减),然后在获得的解决方案的轨迹上执行模仿学习,从而加速训练,同时无需显式确定低级技能或选项就可向学到的策略引入组合性的偏执归纳。上面的示意图是一个任务缩减的具体例子。另外,SIR 可以将学到地任务作为新的缩减目标,从而循环式地学习任意复杂的策略。SIR 通过共同学习一个 goal-conditioned policy 和一个 universal value function 来实现,因此任务缩减可以通过对价值函数的状态搜索和不同目标的策略执行来完成。
作为一个 RL 门外汉,我觉得 intution 还是挺有意思的,不过由于我没细看,我比较好奇这种任务缩减如果没有解决方案已知的简单任务的话怎么办呢?实验是是否需要假设较难的任务都存在解决方案已知的简单任务?(我看 program chair 的最终意见也有差不多的观点,即本文关注的是如何将问题分解为子问题,而在设计任务空间时确实包含了一定先验知识,即并不是学来的。)
- Learning Task Decomposition with Ordered Memory Policy Network
#reinforcement learning #hierarchical imitation learning
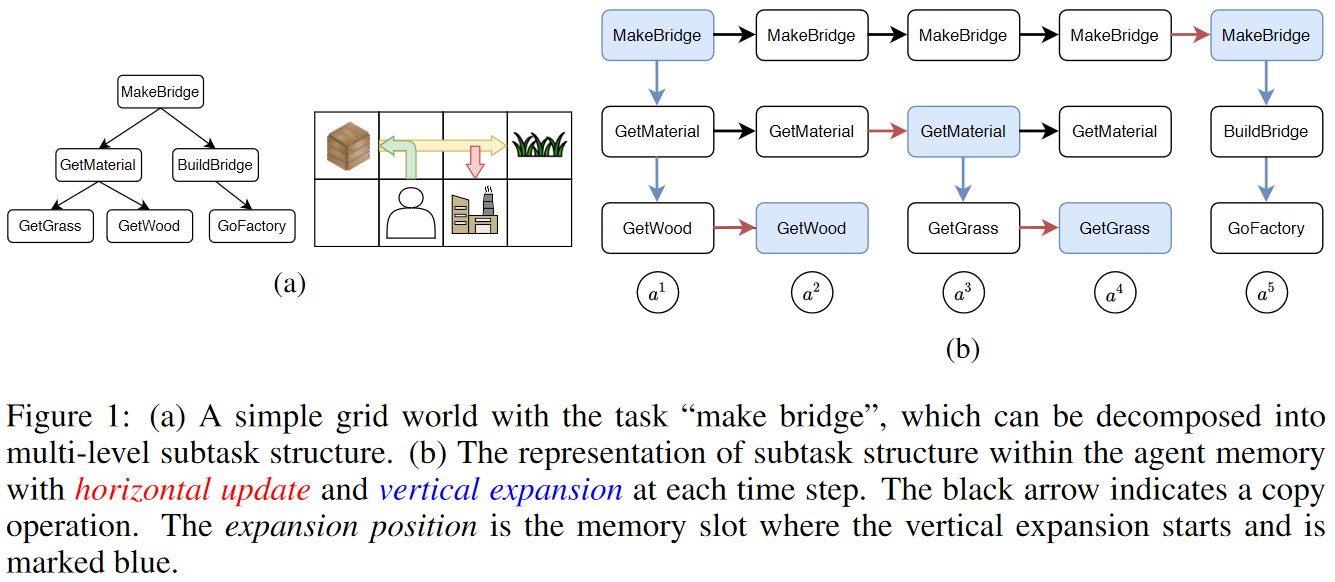
本文提出 Ordered Memory Policy Network (OMPN) ,能够通过从演示中学习来探索子任务的层级结构,从而在监督和弱监督设置下利用非结构化的演示实现任务分解来复用学过的技能。该方法将子任务视为有限状态机(finite state machine),它们被表示为通过自顶向下和自底向上循环更新的内存库。
看 Chap 2.2 开头,还是需要在 detection 阶段让用户给定子任务数量以及动作空间,以生成 task boundaries。
NLP
- Learning to Recombine and Resample Data For Compositional Generalization
#compositional generalization #data augmentation #natural language processing #few-shot morphology learning
本文关注小样本时态学习问题,旨在从单词形式预测包括第三人称、单数、现在时等各种语言特征。以前的工作集中于例如符号语法建模数据或应用基于规则的数据扩增等方法,这些方法很难在没有显式规则的归纳偏置下进行泛化。本文提出一种新的基于原型的神经序列模型,通过显式重组训练示例片段来重构其他输入-输出对,并对模型的输出进行重采样来选择稀有现象的高质量合成样本,从而进行样本扩增。
Continual Learning
- Lifelong Learning of Compositional Structures
#lifelong learning #continual learning #modular networks
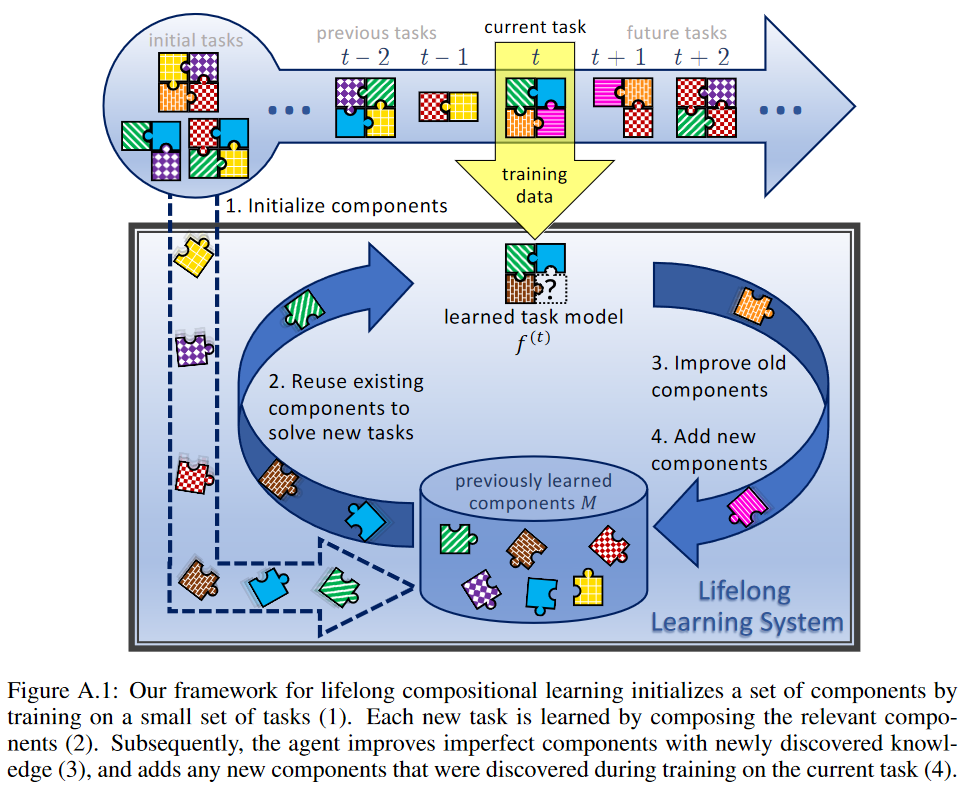
本文将组合学习和终身学习结合,提出一个框架来分阶段地学习如何最佳地组合已有组件来理解新任务,以及如何调整现有组件(以及选择增加新组件)来适应新问题。3x3=9 种组合被用于说明该框架,其中知识保留机制包括简单微调、经验回放(experience replay)、弹性权重整合(elastic weight consolidation);组合性结构包括线性模型的线性组合、软性层排序(soft layer ordering)、门网络的一个软版本(a soft version of gating networks)。八个数据集上的实验结果表明将终身学习过程划分为两个阶段能够减少灾难性遗忘。
generative models
- Using latent space regression to analyze and leverage compositionality in GANs
#image synthesis #generative adversarial networks #image editing
本文使用一个回归器(regressor)来根据属性预测给定图像的隐式编码,从而分析和修改预训练 GAN 的隐式空间。另外编码器的输入可以加上一个 binary mask 来学习在图像不完整的情况进行重构。该方法在图像组合、属性修改、图像补齐和多模态编辑上等应用上都有良好的表现。
我比较感兴趣的是该方法声称能够在图像组合时处理全局不一致和像素缺失的问题;另外研究预训练 GAN 对生成图像的局部进行混合和匹配的能力,而非直接提出新的 GAN 模型的思路也挺有意思(NLP 里很多工作已经是完全建立在预训练模型上进行研究了,当然我不太清楚这种思路是不是也在 GAN 这里成为主流了)。我对引用中 Besserve et al., 2018 有一点兴趣,不过不一定有时间去读。
- The role of Disentanglement in Generalisation
#disentanglement #compositionality #variational autoencoders
本文旨在研究神经网络是否能够利用解纠缠表征来支持组合性泛化和外推。研究建立在两个图像数据集(dSprites 和 3DShape)上,模型包含有不同解纠缠压力的 β-VAEs 和 FactorVAEs,以及去掉编码器的解码器(直接输入解纠缠隐编码)。本文的结论是学习非纠缠表征确实提高了可解释性和样本效率,但这些模型只支持最简单的组合泛化,并且解纠缠的程度对于泛化的程度没有影响。