【paper reading】Prototypical Networks for Few-shot Learning

一直没有完整看过这篇论文。这两天在复现 Prototypical Networks 时发现自己对 metric-based few-shot learning 的认知上存在一些问题,于是决定把这篇经典论文拿出来好好读一遍。
一句话总结
本文提出了原型网络(Prototypical Networks),通过将每个类别的样本求均值得到每个类的原型表示(prototypical representation),简化了 n-shot 分类时 n > 1 的情况,并可以将最近邻分类器成功应用在小样本分类问题上。基于度量学习的小样本学习方法因为这篇经典论文的出世从此自成一派。
论文信息
- 作者:Jake Snell, Kevin Swersky, Richard S. Zemel
- 出处:NIPS 2017
- 机构:Twitter; University of Toronto
- 关键词:few-shot learning, metric learning
- 论文链接
- 开源代码:
- 其他资料:
内容简记
方法
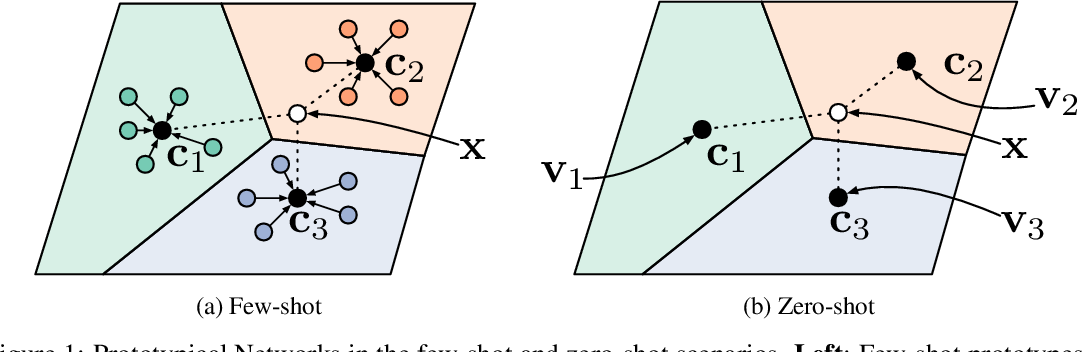
考虑到小样本分类问题上数据量受到限制,分类器应该有一个非常简单的归纳偏执(根据 [1],我认为是因为这样可以减小所需要的样本复杂性)。原型网络(Prototypical Networks)基于“存在一个嵌入空间,使得对于每一类存在一个原型表征,该类中的所有点都围绕着这个原型表征”的假设。在实现上,使用一个神经网络来实现输入到嵌入空间的非线性映射,每类的原型选择嵌入空间中该类的支持集的均值。而对于新的查询样本的分类通过简单地查找最近邻类别原型来实现。
零样本学习问题中,新的(或者说训练阶段不可见的)类别不再包含少量的有标签数据,而是每一类会提供一些元数据(或者称为辅助信息),例如属性、描述等。在实现上,即是每一类有一个元数据向量。因此,对于零样本学习,Prototypical Network 学习将元数据嵌入到一个共享空间中来作为类别原型。也就是说,类别原型和查询原型不来自同一个域。
理论分析
作为混合密度估计
Prototypical Network 的学习过程可以理解为混合概率估计。Bregman 散度是一类特别的距离度量,包含欧式距离和 Mahalanobis 距离。采用 Bregman 散度时,聚类中心即是整个簇最具代表性的点(即质心),使得该类的所有点到质心的总距离之和最小。因此,Prototypical Network 使用类均值作为原型表示,并采用欧氏距离度量。而对于 Matching Network [2] 采用的余弦距离,满足满足和簇的其他点之间总距离最小的质心是使信息损失最小化的点。
作为线性模型进行解释
当使用欧氏距离时 $d\left(\mathbf{z}, \mathbf{z}^{\prime}\right)=\left|\mathbf{z}-\mathbf{z}^{\prime}\right|^{2}$,softmax 的内部可以相当于有特定参数的线性模型。具体来说,将欧式距离展开得到
$$
-\left|f_{\phi}(\mathbf{x})-\mathbf{c}_{k}\right|^{2}=-f_{\phi}(\mathbf{x})^{\top} f_{\phi}(\mathbf{x})+2 \mathbf{c}_{k}^{\top} f_{\phi}(\mathbf{x})-\mathbf{c}_{k}^{\top} \mathbf{c}_{k}
$$
其中,第一项对于类别 k 来说是常量,不影响 softmax 的概率结果;而后两项可以写为
$$
2 \mathbf{c}_{k}^{\top} f_{\phi}(\mathbf{x})-\mathbf{c}_{k}^{\top} \mathbf{c}_{k}=\mathbf{w}_{k}^{\top} f_{\phi}(\mathbf{x})+b_{k}, \text { where } \mathbf{w}_{k}=2 \mathbf{c}_{k} \text { and } b_{k}=-\mathbf{c}_{k}^{\top} \mathbf{c}_{k}
$$
因此变为一个线性模型。
本文猜想,嵌入函数内部已经包含所需要的非线性转换,因此可以直接使用欧氏距离,使得方法更加简单有效。
与 Matching Network 的比较
Matching Network 在给定支持集的情况下生成一个加权最近邻分类器,而 Prototypical Network 使用欧氏距离生成一个线性分类器。当支持集中每个类只有一个样本时,二者等价。Matching Network 有相对复杂的结构,而 Prototypical Network 采用简单的设计达到相当甚至更好的效果。
实验
对比实验
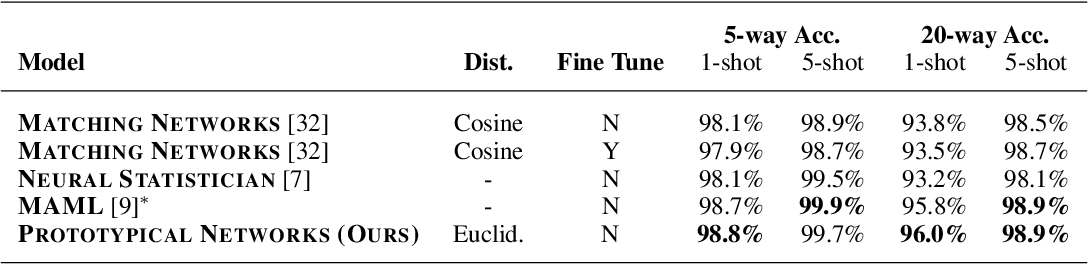
在小样本分类问题上,本文在 Omniglot 数据集上的结果:
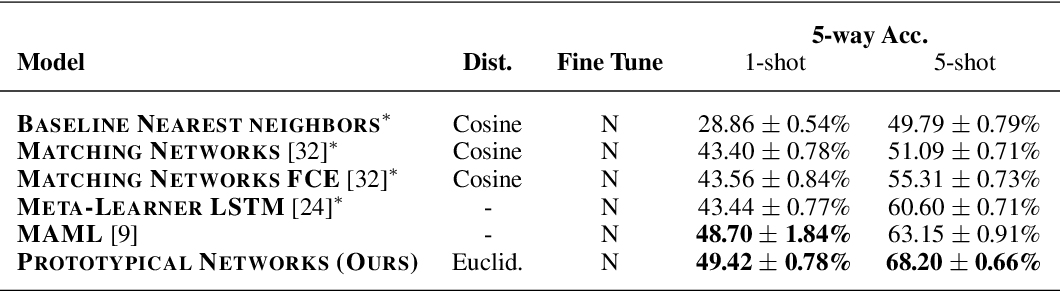
在 miniImageNet 数据集上的结果:
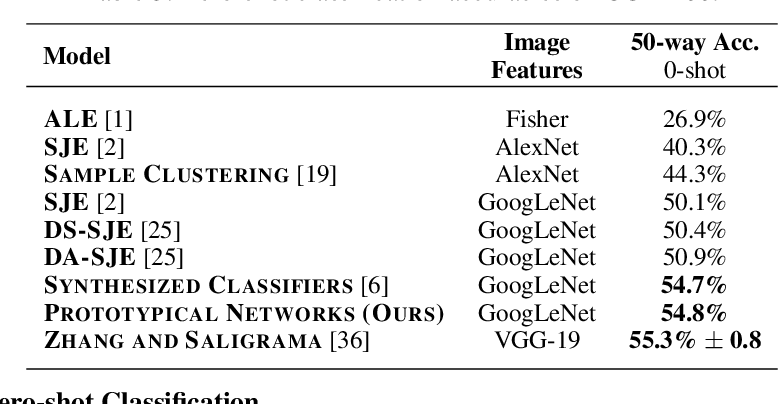
在零样本分类问题上,本文在 CUB 数据集上的结果:
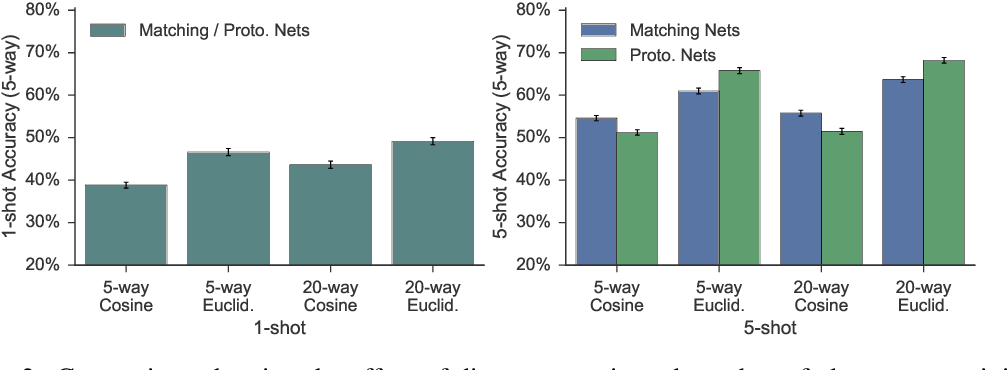
另外有一些有趣的结论。下图的实验结果证明:
- 当训练阶段在一个任务中使用更多的类别数时,测试进行 5-way 分类的结果更好;
- 比起 Matching Network 采用的余弦距离,欧式距离在 Prototypical Network 上的效果更好。原因已在前文进行解释。
个人笔记
实现
简单聊一聊实现上的事情。我之前以为,在 metric-based few-shot learning 中,loss 是从 meta-train 的 training data 上得到的,因此。这是一个没实现过小样本学习方法,只凭借监督问题上的经验容易产生的误区。在小样本学习中,要抛弃掉 training data 和 test data 的概念,用支持集(support set)和查询集(query set)来代表会更好地理解。模型训练阶段的 loss 实际上是由 meta-train 的 query set 得到的,因此,实际上 Prototypical Network 在 meta-test 阶段也不存在微调了,直接用 query prototype 来进行最近邻分类得到准确率。
有一个问题是,零样本学习任务中,本文提出可用固定原型embedding的长度为单位长度,对query embedding不限制。没有很看懂这个设置,这个反映到代码里是怎么实现的?但是源码中没有给出零样本学习部分的代码,有点难受。
参考论文
- [1] Generalizing from a Few Examples: A Survey on Few-Shot Learning, arXiv:1904.05046v2.
- [2] Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638, 2016.