
Attributes-Guided and Pure-Visual Attention Alignment for Few-Shot Recognition
Published in Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI 2021)
Background
The purpose of few-shot recognition is to recognize novel categories with a limited number of labeled examples in each class. To encourage learning from a supplementary view, recent approaches have introduced auxiliary semantic modalities into effective metric-learning frameworks that aim to learn a feature similarity between training samples (support set) and test samples (query set). However, these approaches only augment the representations of samples with available semantics while ignoring the query set, which loses the potential for the improvement and may lead to a shift between the modalities combination and the pure-visual representation. In this paper, we devise an attributes-guided attention module (AGAM) to utilize human-annotated attributes and learn more discriminative features. Contributions are:
-
AGAM utilizes powerful channel-wise and spatial-wise attention to learn what information to emphasize or suppress. While considerably improving the representativeness and discriminability of representations in a fine-grained manner, features extracted by both visual contents and corresponding attributes share the same space with pure-visual features.
-
AGAM applies an attention alignment mechanism between the attributes-guided and self-guided branches. The mechanism contributes to learning the query representations by matching the focus of two branches, so that the supervision signal from the attributes-guided branch promotes the self-guided branch to concatenate on more important features even without attributes.
-
We conduct extensive experiments to demonstrate that the performance of various metric-based methods is greatly improved by plugging our light-weight module.
Model Overview
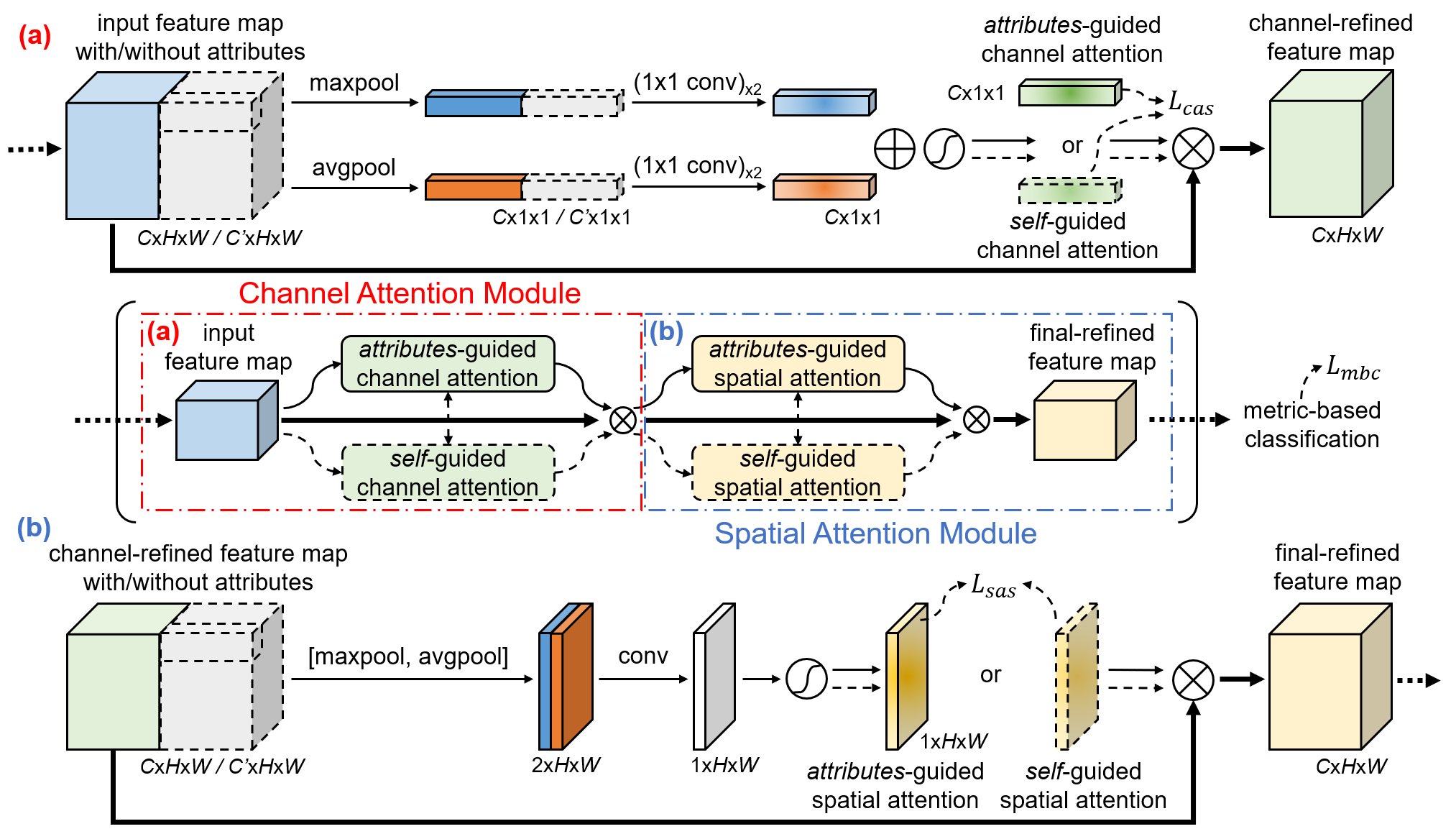
In AGAM, we design two parallel branches, i.e., attributes-guided branch and self-guided branch. For samples with attributes annotations, the attributes-guided branch learns the attention weights by incorporating both attributes and visual contents. And the self-guided branch is designed for the inference of samples without the guidance of attributes. Furthermore, we propose an attention alignment mechanism in AGAM, which aims to pull the focus of the two branches closer, so that the self-guided branch can capture more informative features for query samples without the guidance of attributes. Note that AGAM is a flexible module and can be easily added into any part of convolutional neural networks.
Experiment Results
Here we report some experimental results to empirically show the effectiveness of our AGAM. Please check the paper for the details of the experiment settings and further analysis.
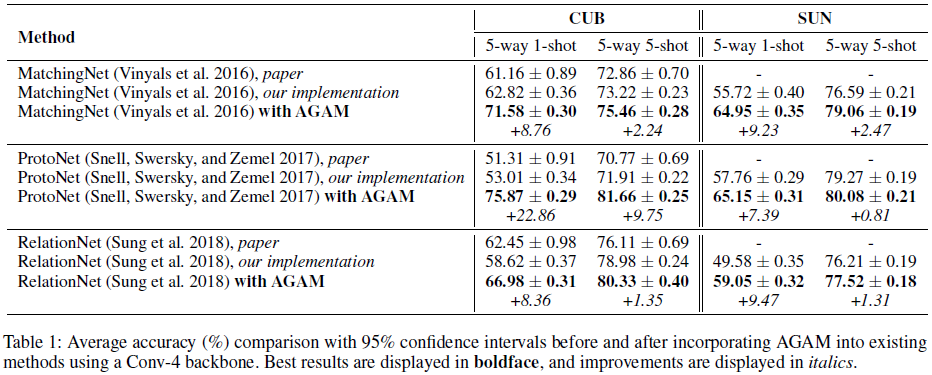
Adapting AGAM into Existing Frameworks
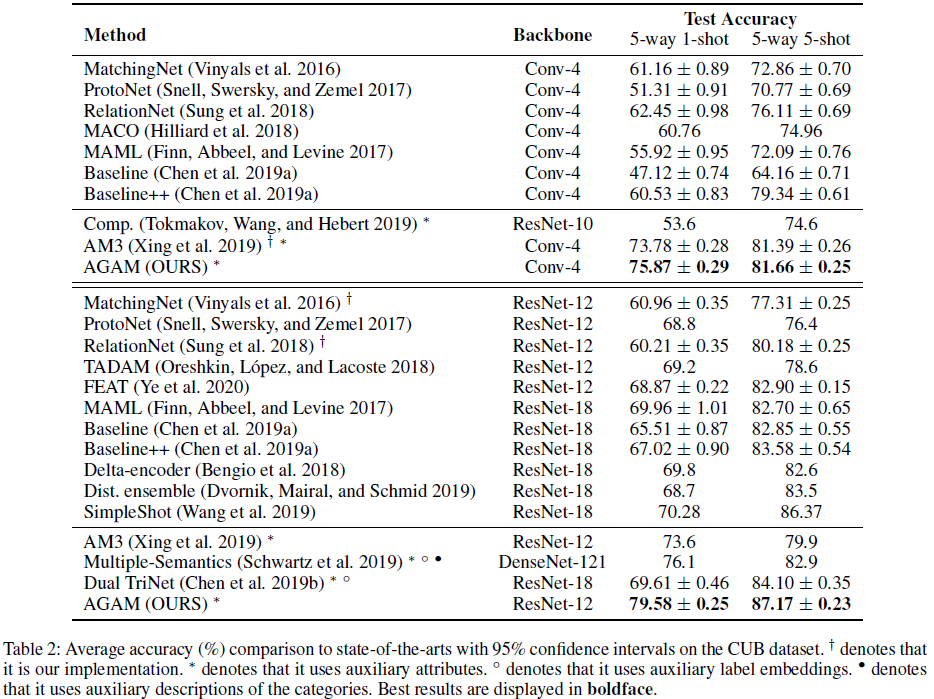
Comparison with State-of-the-Arts
Results on the CUB dataset:
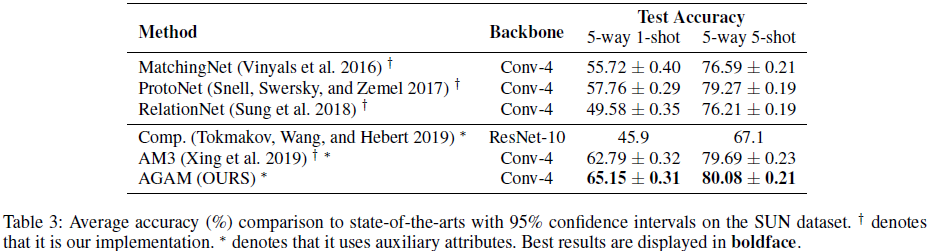
Results on the SUN dataset:
Visualization Analysis

Gradient-weighted class activation mapping (Grad-CAM) visualization of query samples. Each row is the result of the same query sample, and each column is: (a) Original images. (b) Results of Prototypical Network. (c) Results of AGAM but removing the attention alignment mechanism. (d) Results of the complete AGAM. It is observed that incorporating the complete AGAM helps to attend to more representative local features.
BibTex
If our paper and codes are helpful for you research, please cite our paper:
@inproceedings{Huang2021AGAM,
author = {Siteng Huang and Min Zhang and Yachen Kang and Donglin Wang},
title = {Attributes-Guided and Pure-Visual Attention Alignment for Few-Shot Recognition},
booktitle = {Proceedings of the 35th {AAAI} Conference on Artificial Intelligence},
month = {February},
year = {2021}
}