Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Short description of portfolio item number 1
Short description of portfolio item number 2
Published in Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM 2019)
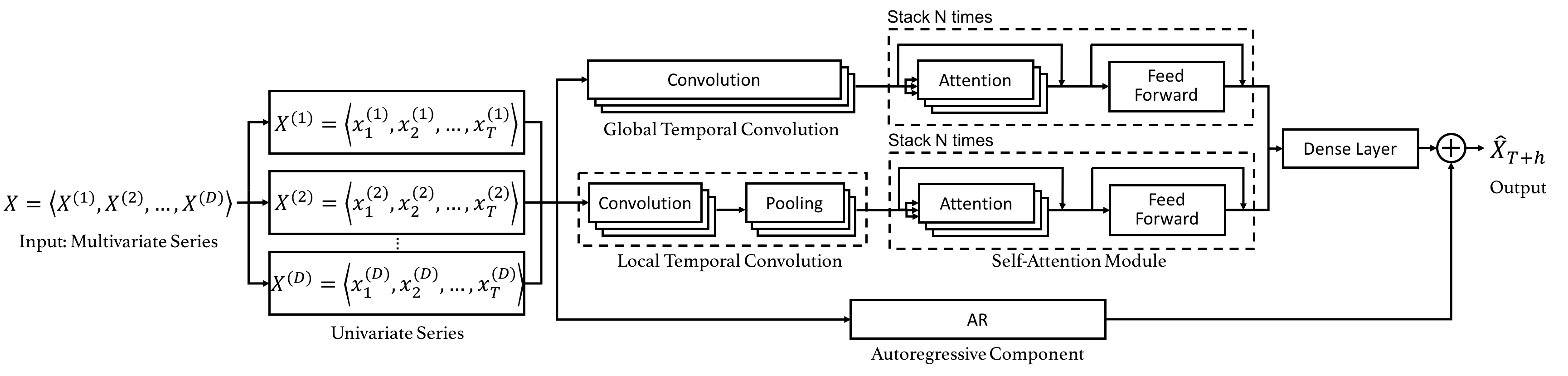 In this paper, we propose a dual self-attention network (DSANet) for multivariate time series forecasting, especially for dynamic-period or nonperiodic series. DSANet completely dispenses with recurrence and utilizes two parallel convolutional components, called global temporal convolution and local temporal convolution, to capture complex mixtures of global and local temporal patterns. Moreover, DSANet employs a self-attention module to model dependencies between multiple series. To further improve the robustness, DSANet also integrates a traditional autoregressive linear model in parallel to the non-linear neural network. Experiments on real-world multivariate time series data show that the proposed model is effective and outperforms baselines.
In this paper, we propose a dual self-attention network (DSANet) for multivariate time series forecasting, especially for dynamic-period or nonperiodic series. DSANet completely dispenses with recurrence and utilizes two parallel convolutional components, called global temporal convolution and local temporal convolution, to capture complex mixtures of global and local temporal patterns. Moreover, DSANet employs a self-attention module to model dependencies between multiple series. To further improve the robustness, DSANet also integrates a traditional autoregressive linear model in parallel to the non-linear neural network. Experiments on real-world multivariate time series data show that the proposed model is effective and outperforms baselines.
Published in Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI 2021)
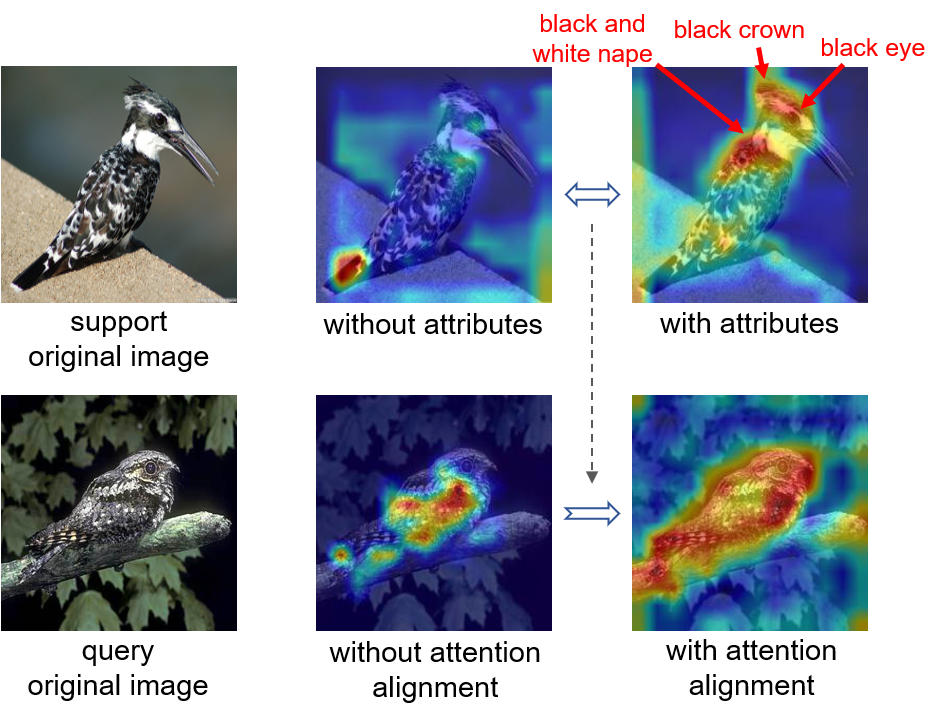
In this paper, we devise an attributes-guided attention module (AGAM) to utilize human-annotated attributes and learn more discriminative features for few-shot recognition. This plug-and-play module enables visual contents and corresponding attributes to collectively focus on important channels and regions for the support set. And the feature selection is also achieved for query set with only visual information while the attributes are not available. Therefore, representations from both sets are improved in a fine-grained manner. Moreover, an attention alignment mechanism is proposed to distill knowledge from the guidance of attributes to the pure-visual branch for samples without attributes. Extensive experiments and analysis show that our proposed module can significantly improve simple metric-based approaches to achieve state-of-the-art performance on different datasets and settings.
Published in Proceedings of the 2023 ACM International Conference on Multimedia Retrieval (ICMR 2023)

While considerable progress has been made on existing benchmarks, we suspect whether popular compositional zero-shot learning (CZSL) methods can address the challenges of few-shot and few referential compositions, which is common when learning in real-world unseen environments. To this end, we study the challenging reference-limited compositional zero-shot learning (RL-CZSL) problem in this paper, i.e., given limited seen compositions that contain only a few samples as reference, unseen compositions of observed primitives should be identified. We propose a novel Meta Compositional Graph Learner (MetaCGL) that can efficiently learn the compositionality from insufficient referential information and generalize to unseen compositions. Besides, we build a benchmark with two new large-scale datasets that consist of natural images with diverse compositional labels, providing more realistic environments for RL-CZSL. Extensive experiments in the benchmarks show that our method achieves state-of-the-art performance in recognizing unseen compositions when reference is limited for compositional learning.
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (CVPR 2023)

In this work, we propose the VoP: Text-Video Co-operative Prompt Tuning for efficient tuning on the text-video retrieval task. The proposed VoP is an end-to-end framework with both video & text prompts introducing, which can be regarded as a powerful baseline with only 0.1% trainable parameters. Further, based on the spatio-temporal characteristics of videos, we develop three novel video prompt mechanisms to improve the performance with different scales of trainable parameters. The basic idea of the VoP enhancement is to model the frame position, frame context, and layer function with specific trainable prompts, respectively. Extensive experiments show that compared to full finetuning, the enhanced VoP achieves a 1.4% average R@1 gain across five text-video retrieval benchmarks with 6× less parameter overhead.
Published in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024)
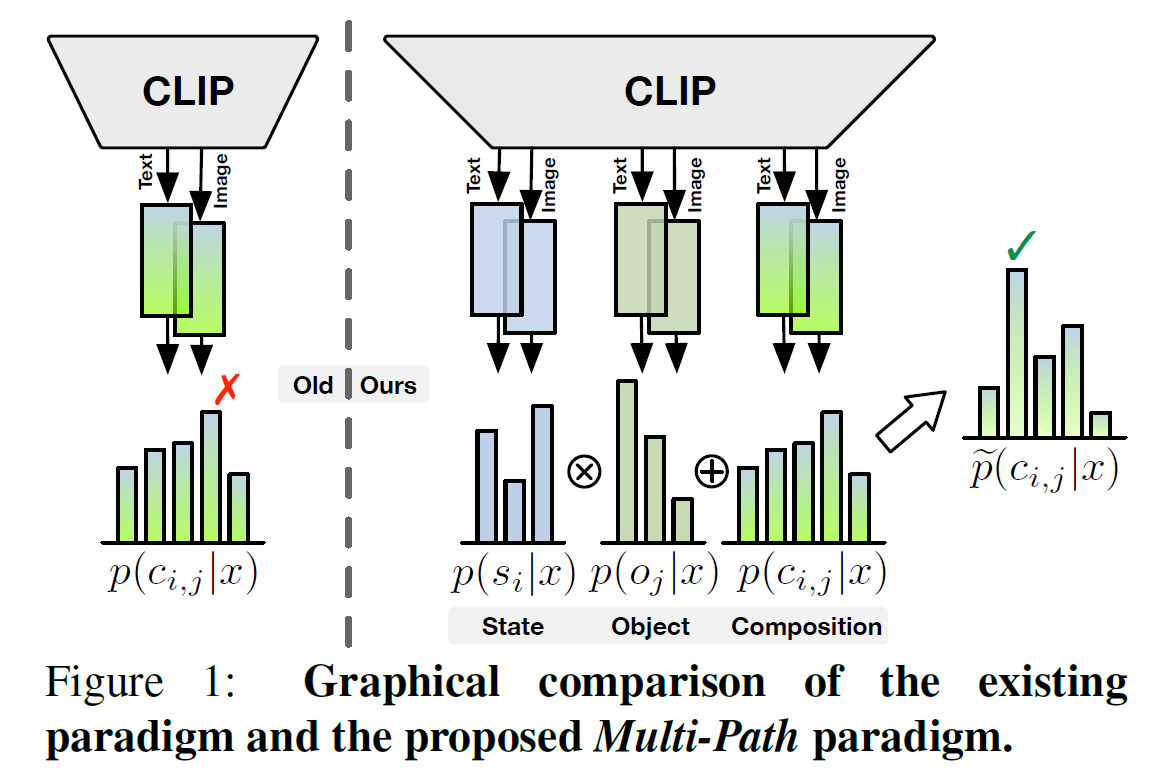
With a particular focus on the universality of the solution, in this work, we propose a novel Multi-Path paradigm for VLM-based CZSL models that establishes three identification branches to jointly model the state, object, and composition. The presented Troika is an outstanding implementation that aligns the branch-specific prompt representations with decomposed visual features. To calibrate the bias between semantically similar multi-modal representations, we further devise a Cross-Modal Traction module into Troika that shifts the prompt representation towards the current visual content. Experiments show that on the closed-world setting, Troika exceeds the current state-of-the-art methods by up to +7.4% HM and +5.7% AUC. And on the more challenging open-world setting, Troika still surpasses the best CLIP-based method by up to +3.8% HM and +2.7% AUC.
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.